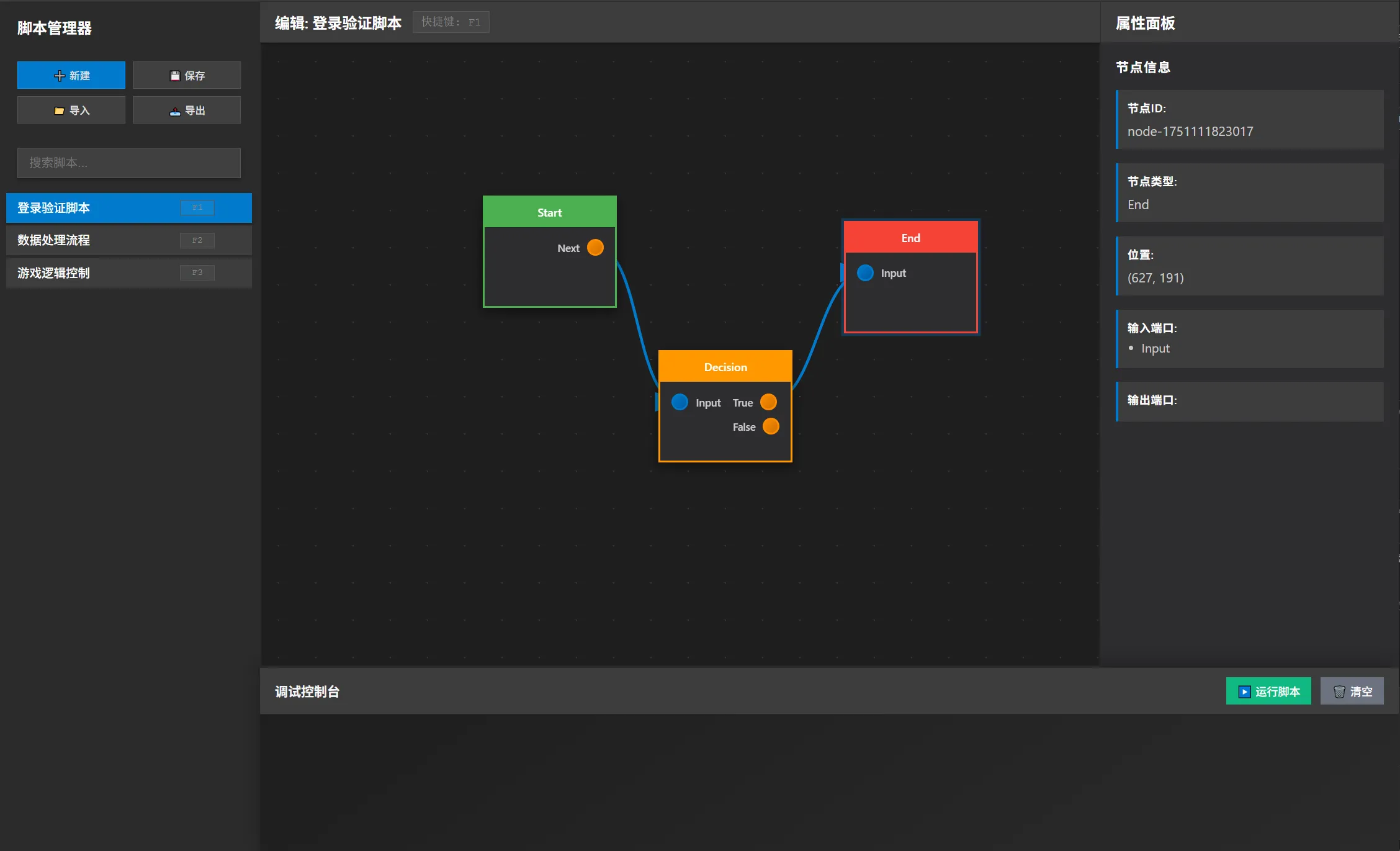
游戏技能配置AI Agent开发记录
前言
前些天牢米也是发布了自己AI GC的进展: https://mp.weixin.qq.com/s/ONKM34FhdrJOoCFFuoeZEA

我看后大为触动,一方面是感叹AI技术进步的如此迅速,另一方面是我看到了行业外的人员参与游戏技能开发的可能性,试想下:一个游戏本身提供足量的脚本节点,玩家的提出的任何设计都能在无需学习技术的情况下被实现,这无疑会大大提高玩家参与游戏社区开发的积极性,这与:ProjectS企划案 的理念不谋而合,所以我也打算对这个方向狠狠的深入研究一番
基础知识
游戏技能本身就是非常复杂,庞大的配置,在和AI交互的时候,可以预见的是,会遇到很多细节性的问题,而这些问题需要有LLM的知识基础,才能更好的解决,所以我先去了解学习了下LLM相关内容:AI GC基础知识总结
总的来说,目前世界上最先进的Claude Sonnet和GPT-5都是很好的推理大语言模型,以及Cursor,Claude Code也是非常出色,非常适用于编程领域的AI Agent的,相信大家在使用中已经完全能感受到了。两者结合完全可以胜任比较简单的技能配置生成和检查,修改工作,但实践下来仍有几个致命问题需要解决:
- 闭源,无法像开源模型一样进行数据微调和再训练,这将导致模型结果始终不够完全可控
- 上下文限制,Agent经常偷懒,忽略了一些重要规则,导致有时结果并不是想要的,即使使用rule来控制,也无法避免,因为他们有时候会忽略rule内容
- 脚本数量庞大,参数庞大的时候,AI很难找到最合适的脚本来编辑技能,轻则性能差劲,重则不可预料的bug
上面这些问题都可以在 本项目实践开源库(初始版本) 进行体验到,这个版本除了rule没有任何额外的辅助,可以感受到原汁原味的LLM开发技能过程中遇到的问题
这些问题如果我们从0开始训练一个专用于技能编辑的LLM模型,一点点整理数据,都是可以解决的,但无疑会耗费非常多的时间和成本,所以比较合适的做法是自己开发编排Agent对LLM进行精细控制,尽可能减少其发散,从而达成可控,稳定的目的,所以本文的内容和目标主要有两个:
- 开发技能专用Agent,规范Agent的行为,让整个技能开发过程更加可控和安全,基于 LangGraph
- 构建技能脚本RAG,让Agent可以适应任意复杂度的项目
RAG
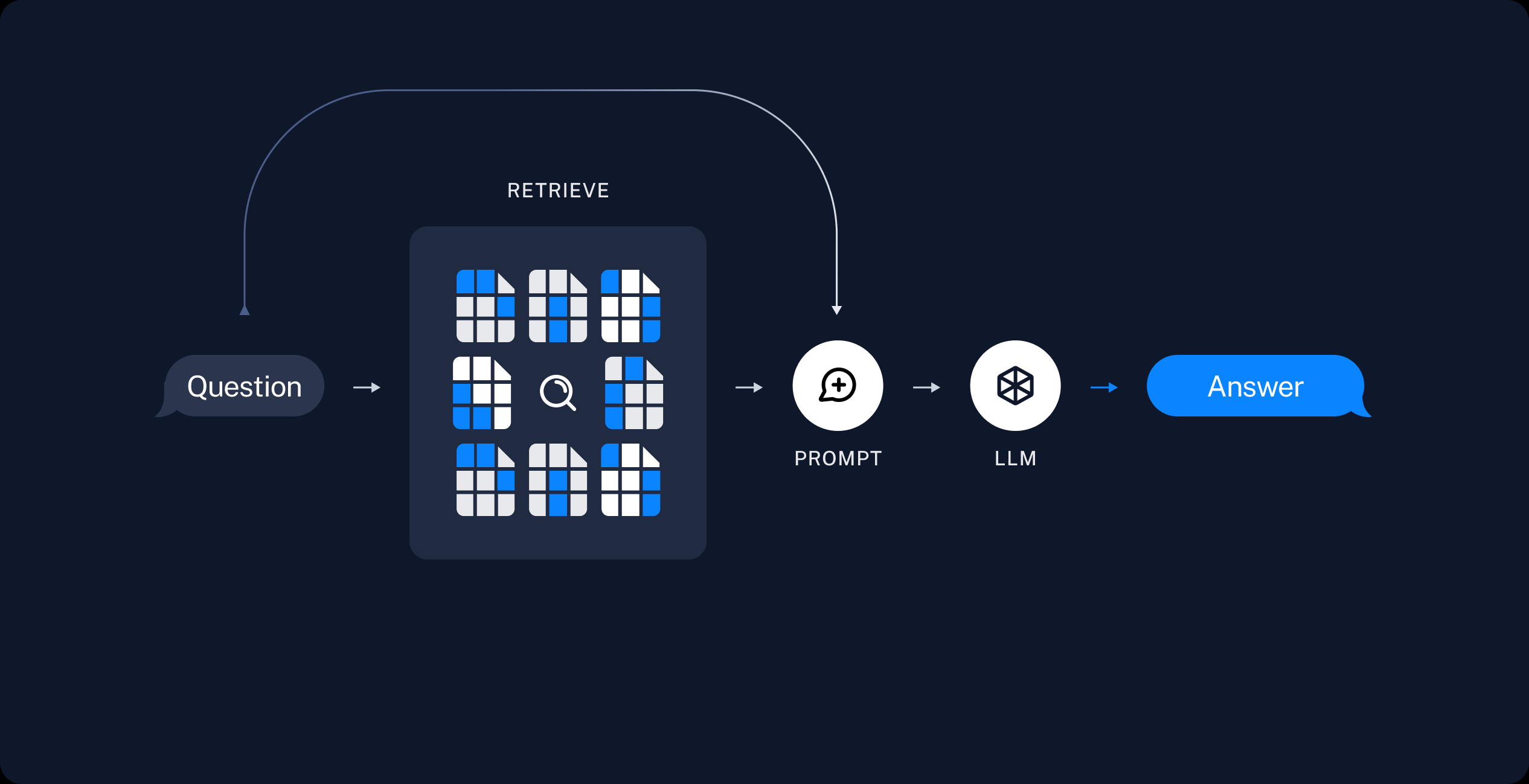
A typical RAG application has two main components:
Indexing: a pipeline for ingesting data from a source and indexing it. This usually happens offline.
Retrieval and generation: the actual RAG chain, which takes the user query at run time and retrieves the relevant data from the index, then passes that to the model.
RAG即Retrieval Augmented Generation(检索增强生成),其主要分为两部分
- 索引 :从数据源提取数据并进行索引的管道。 这通常发生在线下。
- 检索和生成 :实际的 RAG 链,它在运行时接受用户查询并从索引中检索相关数据,然后将其传递给模型。
Index
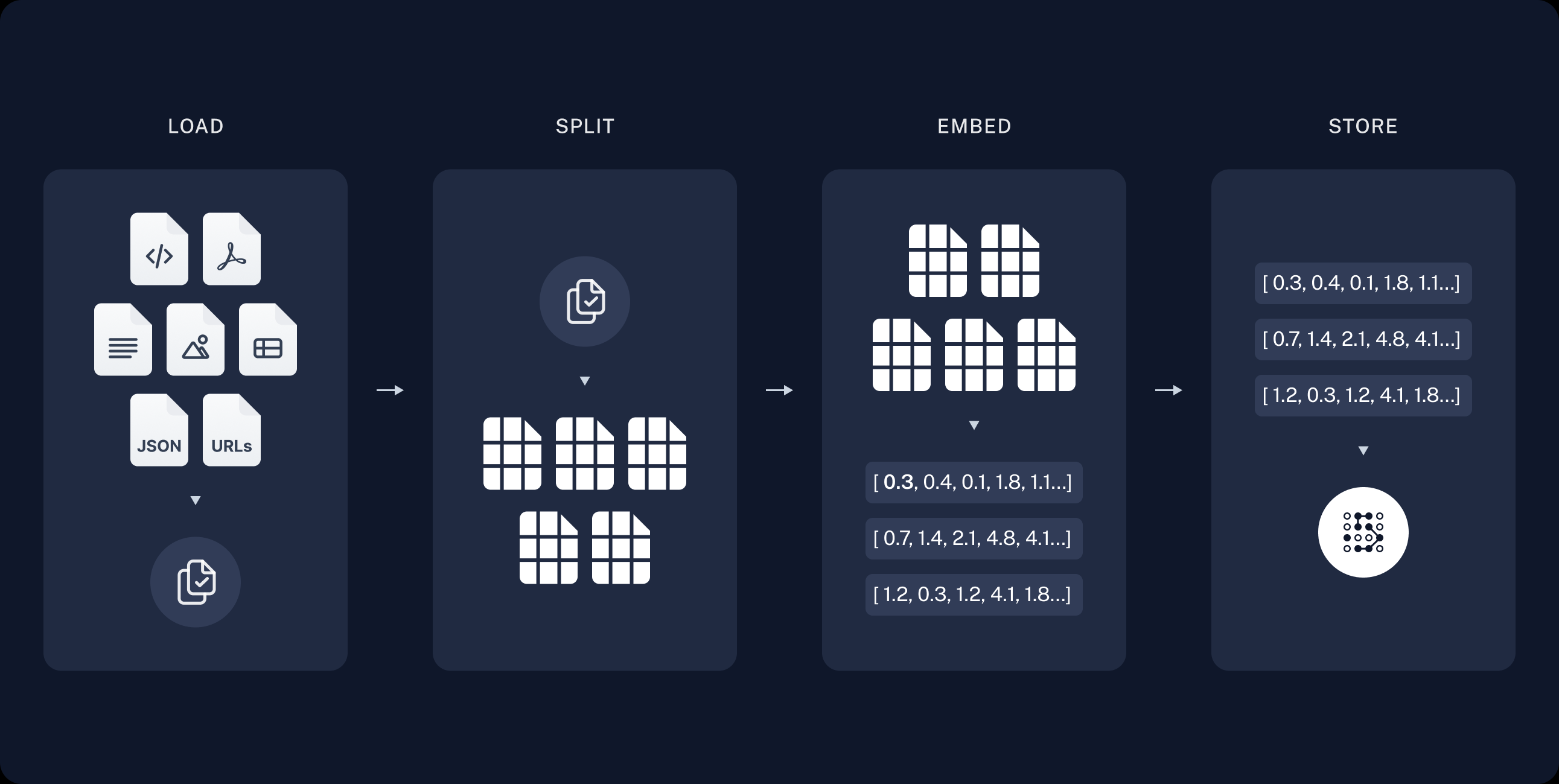
Index本身就是一个构建数据库的过程
- 加载 :首先是技能数据的加载,这里我们直接根据注释生成各个Action文档即可。
- 拆分 : 文本拆分器将大型
Documents拆分成较小的块。这对于索引数据和将其传递到模型都很有用,因为大块数据更难搜索,并且不适合模型有限的上下文窗口。由于技能Action的特殊性:因为我们把每个Action都设计成可复用的,所以其本身就是一个完整的语义单元,所以我们拆分的时候直接以技能脚本为单位拆分Chunk即可 - 存储 :我们需要一个地方来存储和索引我们的分割数据,以便日后进行搜索。这通常使用 VectorStore 和 Embeddings 模型来实现。
Retrieval and generation
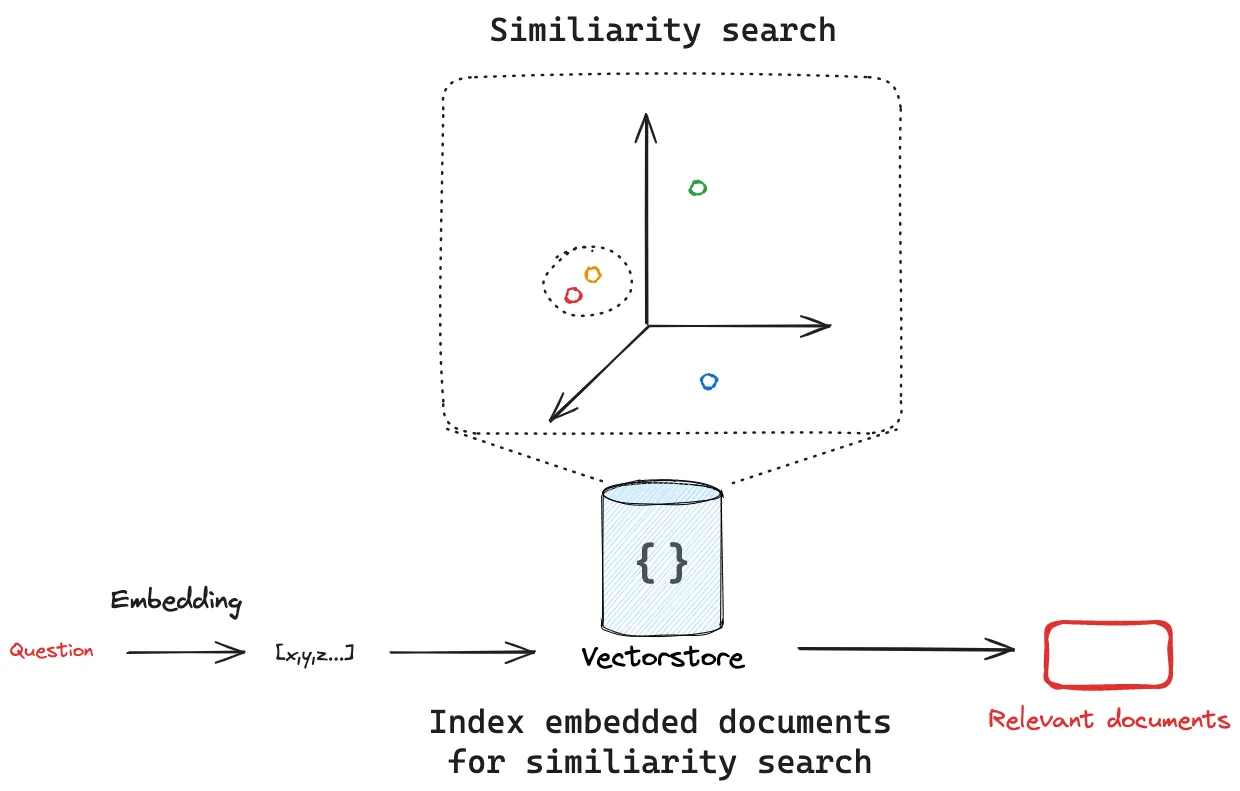
检索和生成一般发生在应用运行的时候
检索 :给定用户输入,使用检索器从存储中检索相关分割。
生成 : ChatModel / LLM 使用包含问题和检索到的数据的提示生成答案
总结
对于RAG的介绍,可以参考:一文读懂:大模型RAG(检索增强生成)含高级方法
简单来说,RAG的功能就是提供一个人机接口,可以让用户用自然语言查询巨量数据的最佳结果,然后继续和LLM交互,从而达到拓展LLM知识的目的
从应用层面来说,从零开始研究RAG是不显示的,所以要用现有的RAG构建方式,可以去 HugeFace 找免费的Embedding模型
RAG的质量直接取决于Embedding Model,我正巧在Claude官方文档看到了 VOYAGE AI ,这是MongoDB公司的产品,而MongoDB是我几年前学习ET框架的时候使用的数据库,其以no sql的形式而广为人知,是一个很老派的数据库开发商了,数据库厂商做Embedding Model,非常合理,可靠,因为他们本身就有非常丰富的大数据处理经验,可惜这个要钱。。。还是选我们的QWen大人吧: https://huggingface.co/Qwen/Qwen3-Embedding-0.6B
基于LangGraph的Agent开发
在 https://www.lfzxb.top/aigc-computer/ 的开发工作中,我几乎算是硬编码实现了一个简单的Agent,大体流程是:通过prompt规范LLM输出内容,然后根据输出内容提取关键字进行function call。体验就是非常不可控,调试了好久的prompt也没法让LLM 100% 输出想要的function call,以至于后续的流程开发也受到影响,推进起来非常困难
实际上我也尝试过Claude Code的Skills机制,要比喻的话就像是一个LangGraph里的插件配置,用自然语言规范Agent的行为,但既然是自然语言规范,自然会有这个通用问题:LLM认为不重要,不听你的话。再加上Claude API对于MCP和Skills的支持非常有限,干脆直接开发一个独立的Agent应用算了,这样我们对LLM有绝对的掌控权
参考
本项目实践开源库
什么是MCP
如何构建MCP
MCP示例
使用C#构建MCP
一文读懂:大模型RAG(检索增强生成)含高级方法
Vector stores
Build a Retrieval Augmented Generation (RAG) App
A Practitioners Guide to Retrieval Augmented Generation (RAG)
 微信
微信 支付宝
支付宝