(译)Introduction To Direct3D 12
本文翻译自:Introduction to Direct3D 12 的前半部分,前半部分讲了一些DX细节,对于理解基础知识很有帮助,后半部分偏实践练习,翻译意义不大。
介绍Direct3D 12
DirectX 12是微软最新一代的DirectX APIS,Direct3D 12是其图形API集合(其余API类型为DirectSound,DirectInput,DirectDraw等)。Direct3D 12比先前的任何一个Direct3D版本表现的都要好,Direct3D提供了对于图形硬件更加底层的控制来允许更加高效的利用多线程。我们可以利用多线程来填充command lists。有更多控制权同时也意味着我们需要承担更多的责任,例如CPU/GPU同步以及内存管理。
Direct3D通过使用预编译的pipeline state objects(PSO)和command lists(bundles)来最小化CPU开销。
在我们应用的初始化阶段,我们会创建很多由shaders(vertex,pixel等)和其他管线状态(blending,rasterizer,primitive topology等)组成的PSO。然后在Runtime过程中,当我们改变渲染管线的时候,驱动不再需要像DX11那样不得不创建管线状态了,取而代之的是,我们提供一个PSO,当我们调用draw的时候,会重复利用我们提供的PSO,这样我们不会再有那些起飞一样的创建管线状态的消耗。
我们也可以在初始化期间创建多组commands,这些命令对于comman lists不同的是,他可以可重复利用,并被称为Bundles MSDN Bundles.另一个很酷的地方是,它的API调用很少,在MSDN中大约有200(其中1/3完成了所有困难的工作)。
初始化 Direct3D 12
- 创建一个设备(device)
- 创建一个命令队列(command queue)
- 创建一个交换链(swap chain)
- 创建一个描述符堆(descriptor heap)
- 创建一个命令分配器(command allocator)
- 创建一个根签名(root signature)
- 编译并创建着色器字节码(Compiling and Creating shader bytecode)
- 创建一个管线状态对象(pipeline state object)
- 创建一个命令列表(command list)
- 创建一个隔离和隔离事件(fence and fence event)
图形管线概览
图形管线 是运行在图形硬件上,被称为*阶段(stages)*的一系列过程。我们将数据推送到流水线中,流水线将在这些阶段中运行数据,以获得表达3D场景的2D图像。我们还能够利用图形管线的流输出阶段(Stream Output Stage)来流式输出被处理的几何图形。一些管线阶段是可以配置的(Fixed Function),而另一些是可以被编程的(Programmable)。那些可编程的阶段被称为着色器(Shaders),它们被使用HLSL编写(HLSL MSDN)。
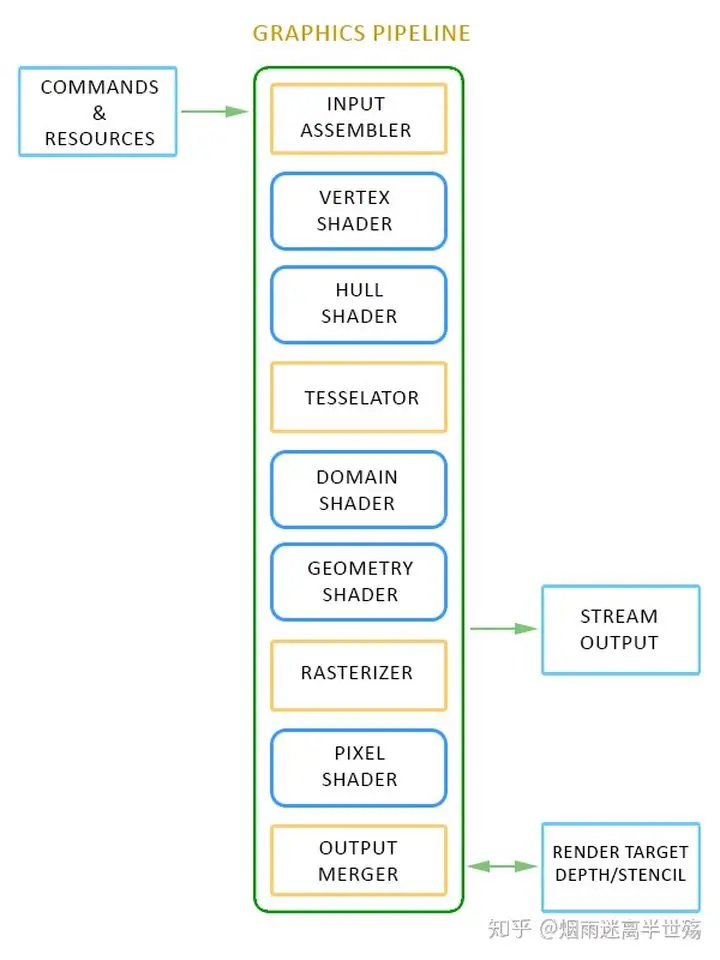
在图形管线中的着色器有:
计算着色器(Compute Shader)
通过使用GPU作为并行处理器来扩展CPU的处理能力,可将计算着色器(也称为Dispatch Pipeline)用于进行极快的计算。这可以和图形没有任何关系,你可以使用计算着色器管线在GPU上执行非常消耗性能的操作,例如精确的碰撞检测。
输入装配阶段(Input Assembler (IA) Stage)
图形流水线的第一阶段被称为输入装配阶段。这是一个固定的功能阶段,这意味着我们不能通过编程来实现它。取而代之的是,我们为device配置它,以便它知道如何从我们提供的包含顶点和索引的缓冲区数据中创建三角形,线和点这样的图元。我们为IA提供一个Input Layout以便它指到如何读取顶点数据。在它把这些数据装配成图元后,它将这些图元输送到图形管线其余阶段。IA还有一些其他的功能,它会将系统生成的值以字符串的形式附加到图元上 (primitive id, instance id, vertex id等)。这些值被称为*语义(Semantics)*,下面是一个示例:
1 | D3D12_INPUT_ELEMENT_DESC layout[] = |
这个input layout告诉IA,每个顶点缓冲区的顶点有一个元素,这个元素应当被限定在顶点着色器中的"POSITION"参数。同时,这个元素会在顶点数据首字节的起始处(第二个参数是0),包含三个浮点数,每个32比特,或者说4字节(第三个参数,DXGI_FORMAT_R32G32B32_FLOAT)。
顶点着色器阶段(Vertex Shader (VS) Stage)
VS是第一个着色器(可编程)阶段,这意味着我们可以定制它。所有由IA阶段装配的图元顶点都要经过VS阶段。使用VS,可以进行诸如变换,缩放,光照,对纹理进行置换贴图之类的操作。为了能让管线正常工作,顶点着色器必须总是实现,即使在程序中的顶点不需要进行更改。最简单的顶点着色器也会简单的将顶点位置传递给下一阶段:
1 | float4 main(float4 pos : POSITION) : SV_POSITION |
顶点着色器简单的返回了输入的位置。注意在pos右边的POSITION,是一个语义的例子。当我们创建我们顶点(input)layout时,我们指定POSITION作为我们顶点的位置值,所以他们将会被发送到VS参数中。如果你想的话,你可以更改POSITION为其他名称。
外壳着色器阶段(Hull Shader (HS) Stage)
HS阶段是被称为(曲面细分阶段)*Tessellation Stages*的三个可选阶段中第一个阶段。Tesselation Stages包括外壳着色器(Hull Shader),曲面细分器(Tessellator),域细分色器阶段(Domain Shader stages)。它们一起工作来实现被称为曲面细分的东西。曲面细分的作用是将一个图元对象(例如一个三角形或者线段)分割成许多较小的部分,从而以极快的速度增加模型的细节。它会在GPU上新建这些图元(当然是在他们显示在屏幕上之前),但是他们不会被保存在内存中,所以这相较于在CPU创建这些图元节省了很多时间(这里意思应该是CPU从内存读取高细节模型)。你可以放一个低模模型,然后使用曲面细分着色器将其转换为超高细节的模型。所以,回到这个Hull Shader,这是一个可编程阶段,这个阶段是用来计算如何,在哪添加新的顶点到一个图元上来让它细节更加丰富。然后把这些数据发送到Tessellator阶段和Domain Shader阶段。
曲面细分器阶段(Tessellator (TS) Stage)
曲面细分器阶段是曲面细分过程的第二个阶段。这是一个固定功能阶段。这个阶段获取从Hull Shader阶段输入的数据,然后真正进行图元的分割,最后将数据传递到Domain Shader阶段。
域细分着色器阶段(Domain Shader (DS) Stage)
这是曲面细分流程的第三个阶段,这是一个可编程功能阶段,这个阶段获取从Hull Shader阶段创建的新顶点的位置,然后变换从tessallator阶段获取的顶点来创建更多细节,在三角形中心或者线段上添加再多的顶点也不会增加任何细节。这个阶段会把这些顶点传递到Geometry Shader阶段。
几何着色器阶段(Geometry Shader (GS) Stage)
这是另一个可选的shader阶段。同时也是另一个可编程阶段。它接收图元作为输入,例如三角形的三个顶点,线段的两个顶点,一个点的一个顶点。它还可以从邻边图元中获取数据作为输入,例如一条线的附加2个顶点,或三角形的附加3个顶点。GS的一个优点是它可以创建或销毁图元(VS无法实现,它只能获取一个顶点并输出一个顶点)。在这一阶段,我们可以将一个点变成四边形或三角形,这使其非常适合在粒子特效引擎中使用。我们能够将数据从GS传递到Rasterizer阶段,和/或通过Stream Output传递到内存中的顶点缓冲区。
流输出阶段(Stream Output (SO) Stage)
该阶段用于从管线中获取顶点数据。从SO发送到内存的顶点数据被放入一个或多个顶点缓冲区。从SO输出的顶点数据始终以列表形式发送,例如线列表或三角形列表。永远不会发出不完整的图元,就像在顶点和几何阶段一样,它们会被无声地分解。所谓不完整的图元,举个例子就是那些只有两个顶点的三角形或只有一个顶点的线。
光栅化阶段(Rasterizer Stage (RS))
RS阶段获取发送给它的向量信息(形状和图元),并通过在每个图元上内插每个顶点值将它们转换为像素。它还处理裁剪,基本上是裁剪屏幕视图之外的图元。这取决于我们所谓的Viewport,可以在代码中进行设置。
像素着色器阶段(Pixel Shader (PS) Stage)
此阶段进行计算并修改将在屏幕上看到的每个像素,例如基于像素的光照。它是另一个可编程着色器,并且是一个可选阶段。RS为图元中的每个像素调用一次像素着色器。就像我们之前说过的那样,在RS中,图元中每个顶点的值和属性都是通过整个图元进行内插的。基本上就像顶点着色器,顶点着色器具有1:1映射(它接受一个顶点并返回一个顶点),而像素着色器也具有1:1映射(它接受一个像素并返回一个像素)。像素着色器的工作是计算每个像素片段的最终颜色。像素片段是将会被绘制到屏幕上的每个潜在像素。例如,在实心圆后面有一个实心正方形。正方形中的像素是像素片段,圆形中的像素也是像素片段。每个像素都有机会写入屏幕,但是一旦进入Output Merger阶段,即决定要绘制到屏幕上的最终像素,它将看到圆的深度值小于正方形深度值,因此只会绘制圆形像素。PS输出4维颜色值。一个简单的Pixel Shader的示例可能如下所示:
1 | float4 main() : SV_TARGET |
这个像素着色器设置所有被绘制在屏幕中的像素的几何图形颜色为白色。基于此着色器,所有将会被绘制的几何图形都会变成白色。
输出合并阶段(Output Merger (OM) Stage)
管线的最后一个阶段是输出合并阶段。最基本的,此阶段获取像素片段和深度/模板缓冲区,并确定实际将哪些像素写入渲染目标。它还基于我们设置的混合模型和混合因子应用混合。渲染目标是Texture2D资源,我们使用device接口将其绑定到OM。场景完成渲染到渲染目标上后,我们可以在swap chain上调用present来显示结果!
概览Direct3D 12是如何工作的
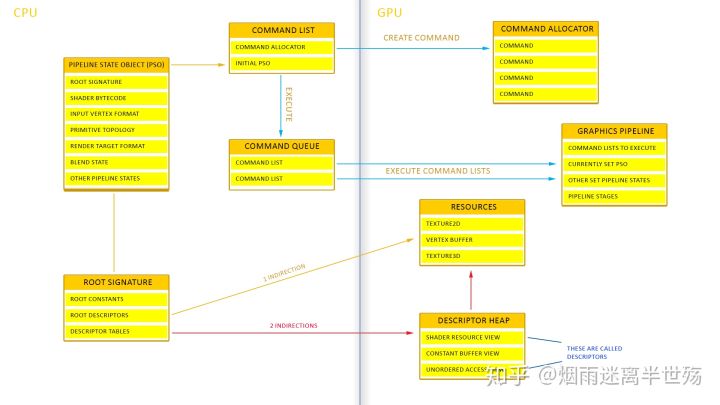
管线状态对象(Pipeline State Objects (PSO))
Pipeline State Object由ID3D12PipelineState接口表示,并由设备接口通过CreateGraphicsPipelineState()方法创建。若要设置Pipeline State Object,可以调用Command List的SetPipelineState()方法。
该接口是使Direct3D 12表现出色的一部分。在初始化期间,您将创建许多此类Pipeline State Objects,然后使用Command List进行设置会占用很少的CPU开销,因为管线状态对象在设置时已经创建完毕,并且在GPU上进行设置就像传递指针那样非常简单。PSO数量不做限制。
创建管线状态对象时,必须填写D3D12_GRAPHICS_PIPELINE_STATE_DESC结构。设置管线状态对象时,此结构将决定管线的状态。
可以在Pipeline State Object中设置大多数管线状态,但是有一些不能在Pipeline State Object中设置,而是由Command List设置。
被PSO设置的状态
-
Shader字节码,包括vertex, pixel, domain, hull, 以及geometry(D3D12_SHADER_BYTECODE)
-
流输出缓冲区(D3D12_STREAM_OUTPUT_DESC)
-
混合状态(D3D12_BLEND_DESC)
-
光栅化状态(D3D12_RASTERIZER_DESC)
-
深度/模板状态(D3D12_DEPTH_STENCIL_DESC)
-
input layout(D3D12_INPUT_LAYOUT_DESC)
-
渲染目标数量
-
渲染目标视图格式(DXGI_FORMAT)
-
深度模板视图格式(DXGI_FORMAT)
-
采样描述(DXGI_SAMPLE_DESC)
被命令列表设置的状态
-
资源绑定 (包括vertex buffers, index buffers, stream output targets, render targets, descriptor heaps, 以及图形根参数(graphics root arguments))
Pipeline State Object设置的管线状态不会被Command Lists或Bundles继承(当Command Queue一次执行多个Command Lists时,在上一个Command Lists设置的Pipeline State Objects管线状态不会被下一个Command Lists继承)(Bundles不会继承由调用Command Lists中的Pipeline State Objects设置的管线状态)。在Command List或Bundle创建时设置Command Lists和Bundles的初始图形管线状态。
未由Pipeline State Object设置的管线状态也不会被Command Lists继承。另一方面,Bundles继承未使用Pipeline State Object设置的所有图形管线状态。当Bundles通过方法调用更改管线状态时,在Bundle完成执行后,该状态将保留回到Command List。
默认图形管线状态为:
-
图元拓扑被设置为 D3D_PRIMITIVE_TOPOLOGY_UNDEFINED
-
视窗被设置为0
-
裁剪矩形被设置为0
-
混合因子被设置为0
-
深度/模板缓冲区被设置为0
您可以通过调用 ClearState 方法将Command List的管线状态设置回默认值。如果在Bundle上调用此方法,则对command lists “close()” 函数的调用将返回E_FAIL。
由Command Lists设置的资源绑定由command list执行的Bundles继承。bundle完成执行后,Bundles设置的资源绑定也将为调用command list保持设置。
设备(The Device)
device由ID3D12Device接口表示。device是一个虚拟适配器,可用于创建command lists,pipeline state objects, root signatures, command allocators, command queues, fences, resources, descriptors和descriptor heaps。计算机可能具有多个GPU,因此我们可以使用DXGI factory来枚举设备,并找到功能级别11(与Direct3d 12兼容)的第一个device而不是软件层的device。 Direct3D最强大的功能之一就是它对于多线程应用程序兼容性更好。
命令列表(Command Lists (CL))
MSDN Command Lists and Bundles
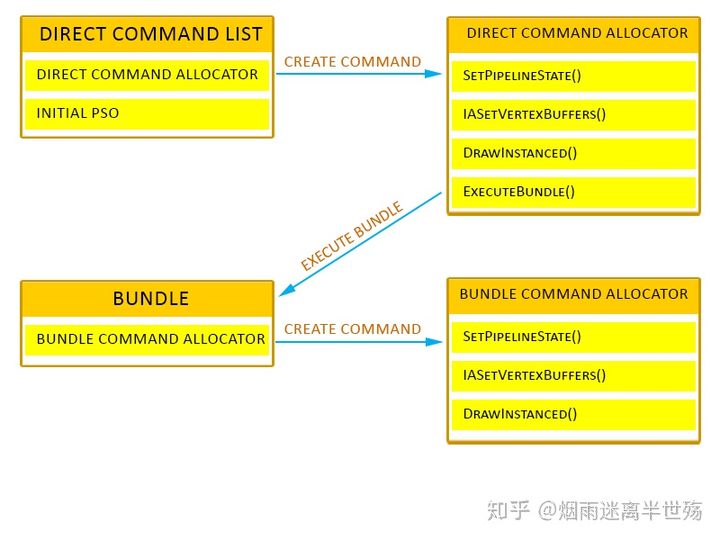
Command lists由ID3D12CommandList接口表示,并由device接口通过CreateCommandList()方法创建。
我们使用Command Lists来分配要在GPU上执行的命令。命令可能包括设置pipeline state, 设置resources, 转换resource states (Resource Barriers), 设置vertex/index buffer, 绘制, 清空render target, 设置render target view, 执行bundles (groups of commands)等。
Command lists与Command Allocator相关联,该Command Allocator将命令存储在GPU上。
首次创建command list时,我们需要使用D3D12_COMMAND_LIST_TYPE标志指定该command list的类型,并提供与该command list关联的command allocator。有四种类型的command lists:direct,bundle,compute和copy。
direct command list是GPU可以执行的command list。direct command list需要与direct command allocator关联(使用D3D12_COMMAND_LIST_TYPE_DIRECT标志创建的command allocator)。
要将Command List设置为记录状态,我们调用command list的Reset()方法,提供Command Allocator和Pipeline State Object。将NULL作为Pipeline State Object的参数传递是有合法的,并且将设置默认管线状态。
当我们完成command list的填充时,我们必须调用close()方法以将command list设置为非记录状态。调用close之后,我们可以使用Command Queue执行command list。
一旦执行了command list,即使GPU尚未完成,我们也能够将其重置(一旦调用execute,则由Command Allocator存储在GPU上运行的命令)。这使我们可以重用分配给command list的内存(在CPU端,而不是在由Command Allocator将命令存储在内存中的GPU端)。
捆绑包(Bundles)
MSDN Command Lists and Bundles
Bundles由ID3D12CommandList接口表示,与Direct Command Lists相同,唯一的区别是创建bundle时(通过调用CreateCommandList()方法),使用D3D12_COMMAND_LIST_TYPE_BUNDLE标志而不是D3D12_COMMAND_LIST_TYPE_DIRECT标志来创建bundle。
Bundles是一组经常重复使用的命令。它们很有用,因为与命令组有关的大多数CPU工作都是在bundle创建时完成的。在大多数情况下,Bundles与Command Lists相同,只是bundles只能由Direct Command List执行,而Direct Command List只能由Command Queue执行。可以重复使用Command Lists,但是在再次调用该command list上的execute之前,GPU必须先完成该command list的执行。在实践中,您几乎不可能重用command list,因为场景会在帧之间变化,这意味着command list会在帧之间变化。
Nvidia上有一篇不错的文章,介绍了Direct3D最佳实践(DX12 Do’s And Don’ts),并传达了他们的建议,bundle 最多只能包含约12条命令,否则,如果添加太多命令,bundle的可重用性将受到削弱,这意味着您将无法经常重复使用它。最好创建许多可以经常重用的小bundles,而不是创建几个您不经常重用的大bundles,因为bundles的全部是可重用的命令组。
Bundles不能直接从Command Queue中执行。您可以通过从Direct Command List调用ExecuteBundle()在Command List上执行bundle 。
Bundles不继承调用Direct Command List设置的管线状态。
命令队列(Command Queues (CQ))
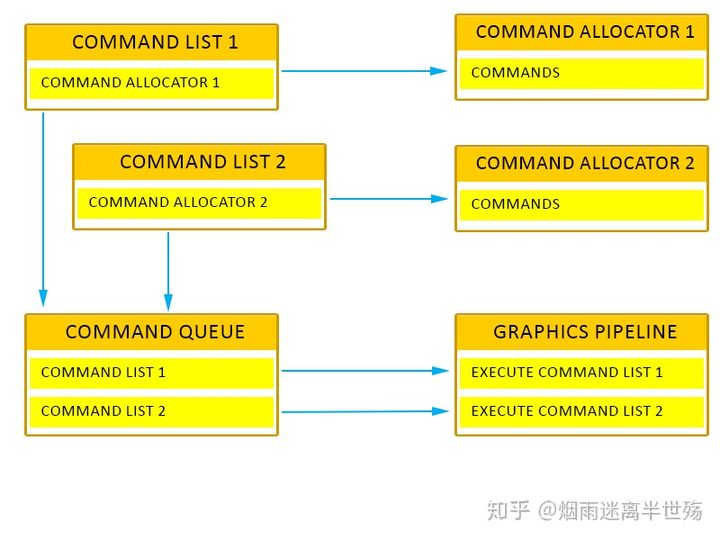
Command Queues由ID3D12CommandQueue接口表示,并且由device接口的CreateCommandQueue()方法创建。我们使用command queue来提交将要由GPU执行的Command Lists。Command Queues也会被用于更新资源块映射(resource tile mappings)。
命令分配器(Command Allocators (CA))
Command Allocators由ID3D12CommandAllocator接口表示,并使用device接口的CreateCommandAllocator()方法创建。
Command Allocators表示用于存储来自Command Lists和Bundles的命令的GPU内存。
一旦Command List执行完毕,您可以在Command Allocator上调用reset()释放内存。尽管可以在执行Command Queue调用后立即在Command List上调用reset(),但在调用reset()之前,与Command Allocator关联的Command List必须在GPU上完全完成执行,否则调用将失败。这是因为GPU可能正在执行存储在Command Allocator表示的内存中的命令。这也是我们的应用程序必须使用Fences同步CPU和GPU的原因。在对Command Allocator调用reset()之前,必须检查围栏(fence)以确保与Command Allocator关联的Command List已完成执行。
只有一个任何Command List关联一个Command Allocator的时候才可以在任何时候都处于记录状态。这意味着对于每个填充command lists的线程,您将需要至少一个Command Allocator和至少一个Command List。
资源(Resources)
资源包括构建场景的数据。他们是用于存储几何图形,纹理和shader数据的成块的内存,图形管线可以从这些内存中访问到它们。资源类型是资源包含的数据类型。
Resource Types
Resource References/Views
-
Constant buffer view (CBV)
-
Unordered access view (UAV)
-
Shader resource view (SRV)
-
Samplers
-
Render Target View (RTV)
-
Depth Stencil View (DSV)
-
Index Buffer View (IBV)
-
Vertex Buffer View (VBV)
-
Stream Output View (SOV)
描述符(资源视图)(Descriptors (Resource Views))
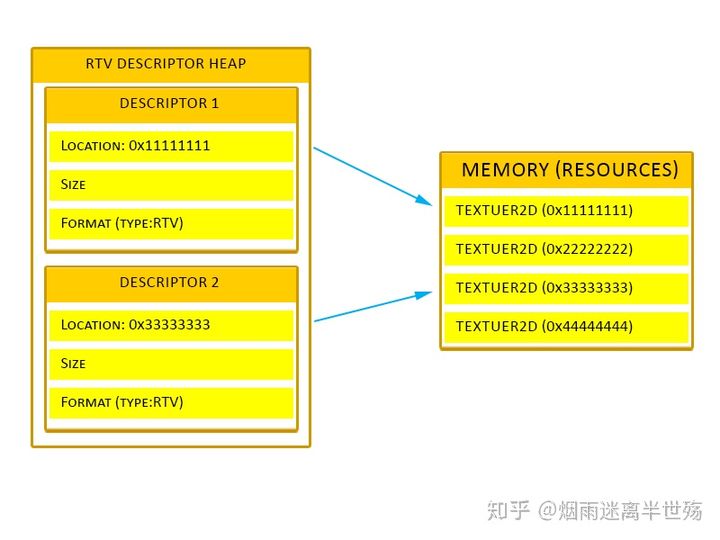
描述符是一种结构,它告诉着色器在哪里可以找到资源以及如何解释资源中的数据。就像在D3D11中查看资源视图那样,您可以在D3D12中查看资源描述符。您可能会为同一资源创建多个描述符,因为管线的不同阶段可能会不同地使用它。例如,我们创建一个Texture2D资源。我们创建一个“渲染目标视图”(RTV),以便可以将该资源用作管线的输出缓冲区(将该资源作为RTV绑定到“输出合并”(OM)阶段)。我们还可以为同一资源创建一个无序访问视图(UAV),我们可以将其用作着色器资源并使用其纹理化几何图型(例如,如果场景中某处有监控摄像机,则可以执行此操作。我们将摄像机看到的场景渲染到资源(RTV)上,然后我们将该资源(UAV)渲染到安全室中的电视上。)
描述符只能放在描述符堆(Descriptor Heaps)中。没有其他方法可以将描述符存储在内存中(某些根描述符(只能是CBV的根描述符)以及原始的或结构的UAV或SRV缓冲区除外。像Texture2D SRV这样的复杂类型不能用作根描述符)。
描述符表(Descriptor Tables (DT))
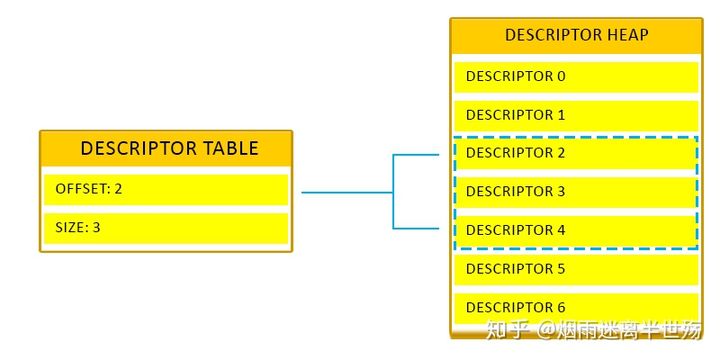
描述符表是描述符堆中的描述符数组。所有描述符表都是描述符堆的偏移量和长度。
着色器可以通过根签名的描述符表按索引访问描述符堆中的描述符。因此,要访问着色器中的描述符,您将索引到根签名描述符表。
CBV,UAV,SRV和采样器存储在描述符堆中,并且可以由着色器的描述符引用。
RTV,DSV,IBV,VBV和SOV并非通过描述符表进行引用,而是直接绑定到管线。MSDN文档在这部分内容上有些令人困惑,因此说实话,我对此并不完全确定,但是MSDN说这些没有存储在描述符堆中,但是对于RTV而言,并不是完全正确的,DSV和SOV,因为您需要为其创建堆和描述符。据我了解,没有其他方法可以创建它们。
描述符堆(Descriptor Heaps (DH))
描述符堆由接口ID3D12DescriptorHeap表示,并使用方法ID3D12Device::CreateDescriptorHeap()创建。描述符堆是描述符的列表。它们是存储描述符的一块内存。
采样器不能与资源进入相同的描述符堆。描述符堆也可以是**“着色器可见”或“非着色器可见”**。着色器可见描述符堆是包含着色器可以访问的描述符的堆。这些类型的堆可能包括CBV,UAV,SRV和Sampler描述符。非着色器可见描述符堆是着色器无法引用的堆。这些类型的堆包括RTV,DSV,IBV,VBV和SOV资源类型。法线贴图可能具有三个描述符堆,一个用于采样器,一个用于着色器可见资源,一个用于非着色器可见资源。
在任何时候,只能将一个着色器可见堆和一个采样器堆绑定到管线。您希望描述符堆在最长时间内具有正确的描述符(根据MSDN,“理想情况下是整个渲染帧或更多”)。描述符堆必须有足够的空间来为每个所需状态集动态定义描述符表。为此,您可以在管线状态改变时重用描述符空间(例如,正在渲染一棵树,在描述符堆中有一个描述符,该描述符在绘制树干时指向树皮的UAV。当您需要绘制树的叶子时,管线会发生变化,因此您可以通过将树皮纹理的UAV替换为叶子纹理的UAV来重用树皮纹理的UAV。)
D3D12允许您在command list中多次更改描述符堆。这非常有用,因为较旧的低功耗GPU仅具有65k的描述符堆存储空间。更改描述符堆会导致GPU“刷新”当前的描述符堆,这是一项昂贵的操作,因此您希望尽可能少地执行此操作。
Bundles仅允许调用一次SetDescriptorHeaps,并且此命令设置的描述符堆必须与调用bundle的command list已设置的描述符堆完全匹配。
有两种管理描述符堆的方法,这里有两种(在MSDN文档中提到了这些方法):
基本方法(效率低下,但很容易实现)
第一种方法(也是最基本的方法)就在绘制调用之前,将绘制所需的所有描述符添加到描述符堆,然后在根签名中设置一个描述符表以指向新的描述符。这种方法很好,因为不需要跟踪描述符堆中的所有描述符。但是,由于我们将对绘制调用的所有描述符都添加到了堆中,因此在堆中将有很多重复的描述符,这使得该方法非常拉跨,尤其是在渲染相似的对象或场景时。
我们必须在描述符堆中的可用空间中添加新的描述符,而不是覆盖先前绘制中描述符堆中已经存在的描述符的原因,是因为GPU实际上可以同时执行多个绘制调用,这意味着我们开始为当前绘制覆盖描述符A时,可能会在描述符堆中仍然使用A。
使用此方法,由于以下一个或两个原因,您可能需要一个附加的描述符堆:场景又大又复杂,描述符空间用完了,或者可能存在同步问题,因此您有一个用于GPU读取的描述符堆,然后在GPU执行命令列表时用CPU填充另一个描述符堆,然后在每一帧交换这两个堆。
第二种方法(效率更高,更难以实施)
另一种方法是跟踪描述符堆中每个描述符的索引。这种方式非常高效,因为您可以为相似的对象和场景重用描述符。这种方法是高效的,因为在描述符堆中很少有完全不重复的描述符。这种方法的缺点是实现起来有点复杂。
如果您的场景足够小,并且没有在整个场景中更改的资源,则实际上可以创建一个巨型描述符表,并在场景结束时刷新该对象,然后需要重新加载新资源。如果在整个场景中唯一改变的是根常量和根描述符,那么这将起作用。描述符表(在根签名中定义)将在整个场景中保持不变。
进行一些优化的其他几种方法是在描述符堆中有两个描述符表。一个描述符表的资源在整个场景中不会改变,而另一个描述符表的资源则经常变化。
您将要做的另一件事是确保根常量和根描述符包含最频繁更改的常量和描述符。
根签名(Root Signatures (RS))

根签名定义了着色器访问的数据(资源)。根签名就像一个函数的参数列表,其中函数是着色器,而参数列表是着色器访问的数据类型。
根签名包含根常量,根描述符和描述符表。根参数是根签名中的一项,可以是根常量,根描述符或描述符表。应用程序可以更改的根参数的实际数据称为**“根参数”**。
根签名的最大大小始终为64 DWORDS。
根常数(Root Constants)
根常量是内联32位值(它们的成本为1 DWORD)。这些值直接存储在根签名中。由于内存被限制在根签名,因此您只想在此处存储着色器访问的最常更改的常量值。这些值显示为着色器的恒定缓冲区。从着色器访问这些变量没有成本(无需重定向),因此访问它们非常快。
根描述符(Root Descriptors)
根描述符是内联描述符,着色器最常访问的就是内联描述符。是64位虚拟地址(2个DWORD)。这些描述符仅限于CBV,原始或结构化SRV和UAV。不能使用诸如Texture2D SRV之类的复杂类型。从着色器引用根描述符时,需要进行一次重定向。关于根描述符的另一件事要注意的是,它们只是指向资源的指针,它们不包含数据的大小,这意味着从根描述符访问资源时不能进行越界检查,这与存储在描述符堆中的描述符不同(确实包括大小,并且可以在其中进行边界检查)。
描述符表(Descriptor Tables)
上面讨论过,描述符表是描述符堆的偏移量和长度。描述符表只有32位(1个DWORD)。描述符表中有多少个描述符没有限制(但是会被限制于描述符堆的描述符数量)。从描述符表访问资源时,存在两个间接开销。第一个间接方法是从描述符表指针到存储在堆中的描述符,然后从描述符堆到实际资源。
资源屏障Resource Barriers
资源屏障用于更改资源或子资源的状态或使用情况。Direct3D 12在其多线程友好的API中引入了资源屏障。资源屏障用于帮助在多个线程之间同步资源的使用。
资源屏障有三种类型:转换屏障,混叠屏障和无序访问视图(UAV)屏障。
转换屏障
当您要将资源或子资源的状态从一种状态转换到另一种状态时,可以使用转换屏障。何时更改资源状态的一个示例是在翻转交换链之前将资源从渲染目标状态更改为当前状态。
混叠屏障
混叠屏障与Tiled Resources一起使用。这些屏障用于更改具有映射到同一个图块池(same tile pool)(来自msdn)的两个不同资源的用法。
无序访问视图(UAV)屏障
UAV屏障用于确保在调用此屏障之前完成所有读/写操作。例如,如果正在写入UAV,此时来了一个draw call,在执行draw call之前完成对UAV的写入。无需在仅从UAV读取的两个绘制或者调用之间创建UAV屏障。如果同一UAV被两个不同的绘制或调用写入,也不需要,只要应用程序确定一个在另一个开始之前就已经完全完成即可。如果要绘制纹理,则可以在UAV上使用UAV屏障,然后使用该纹理在模型上绘制。在将UAV用作模型上的纹理之前,UAV屏障将确保绘制到UAV的调用已完成。
隔离和隔离事件(Fences and Fence Events)
作为DirectX 12的底层的一部分,我们可以将命令队列发送到GPU以开始执行,然后可以立即在CPU上再次开始工作。为了确保我们不修改或删除GPU当前正在使用的内容,我们使用隔离。 Fences和Fence Events将让我们知道GPU在执行命令队列时的位置。在此应用中,我们要做的是告诉GPU执行命令队列,更新游戏逻辑,检查/等待GPU完成执行命令队列,通过将更多命令查询到命令列表中来更新管线,然后再次执行执行命令队列。**首先用命令填充命令列表,执行命令队列,发信号通知命令列表以将隔离值设置为指定值,然后检查隔离值是否是我们告诉命令列表将其设置为的值。如果是这样,我们知道命令列表已完成其中的命令,可以重置命令列表和队列,然后重新填充命令列表。如果fence值仍然不是我们所指示的值,那么我们创建一个fence事件并等待GPU发出信号。**隔离由ID3D12Fence接口表示,而隔离事件是句柄HANDLE。device使用ID3D12Device::CreateFence方法创建隔离,并使用CreateEvent()方法创建隔离事件。
概览Direct3D 12应用的流程控制(Overview of Application Flow Control for Direct3D 12)
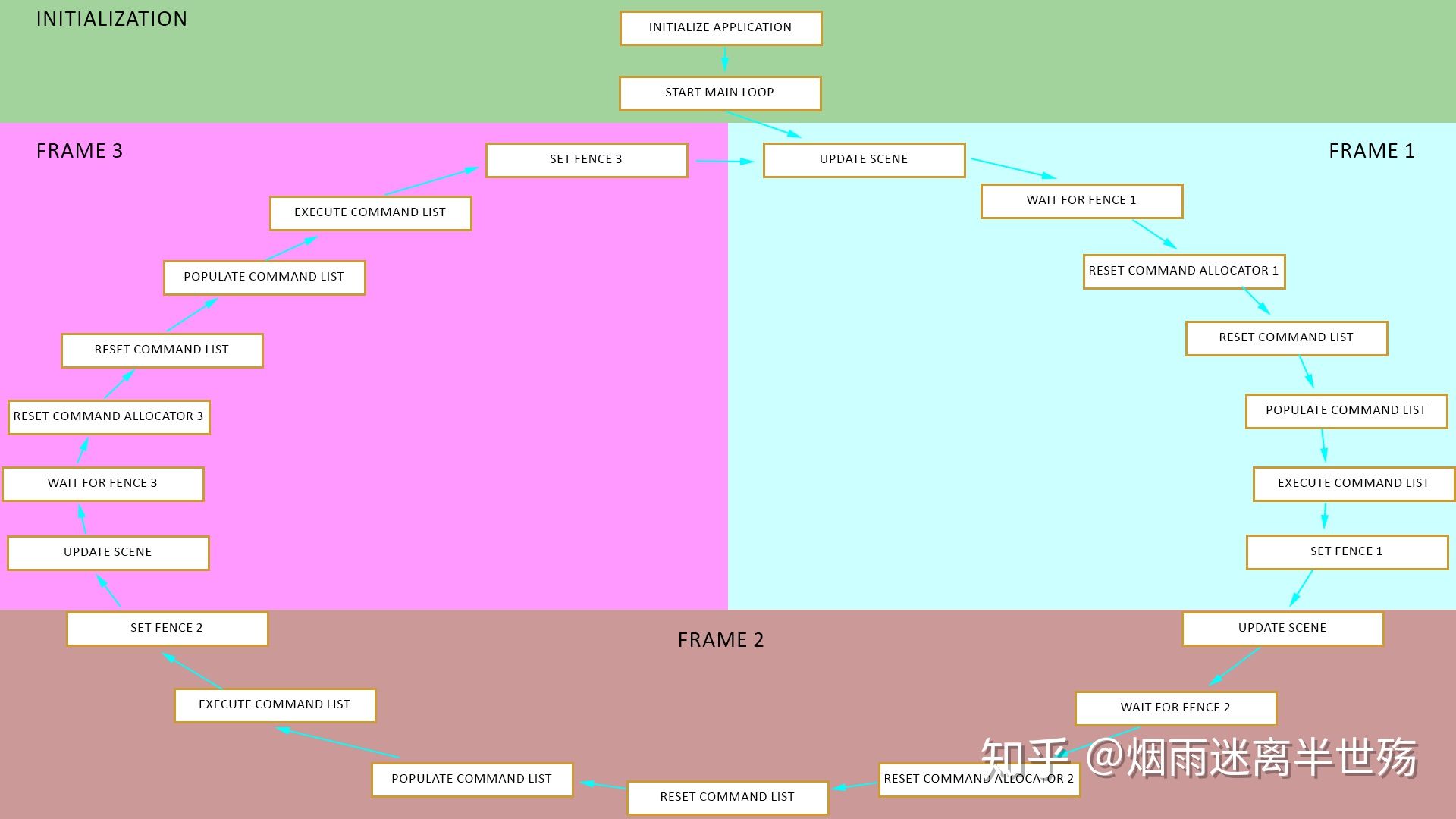
这是Direct3D的经典模型:
- 初始化应用程序
- 启动主循环
- 构建场景(如果是新场景的话)
- 更新游戏逻辑
- 加载/释放资源(如果需要的话)
- 等待GPU
- 重置命令分配器和命令列表
- 填充任务列表
- 如果是是多线程的话,等待任务列表线程
- 执行任务列表
- 回到第三步
1. 初始化应用程序
此阶段可能包括以下内容:
-
从文件或数据库加载设置
-
确保这是应用程序的唯一实例
-
检查更新
-
检查内存申请
-
检查许可证 (例如体验版,Demo版甚至是盗版)
-
创建一个窗口
-
初始化脚本引擎
-
构建资源管理器
-
构建音频系统
-
构建网络
-
构建控制器
-
初始化Direc3D
-
构建描述符堆(Descriptor heap manager,如果有的话)
-
构建命令列表
-
构建RTV
-
构建命令分配器
-
构建所有的PSO(你将会有很多PSO)
-
构建所有的根签名(通常来说你只需要一个)
-
2.开始主循环
可以在这里开始主循环,检查windows窗口事件,如果没有,就更新游戏。
3.构建场景
当然,这是在主循环内,因为您的游戏中可能有很多场景。您当然可以做任何想做的事,但是通常情况下,场景变化时不必退出主循环。此阶段包括以下内容:
-
加载整个场景所需的资源(直到场景改变或玩家退出时才释放这些东西)。这包括纹理,几何图形,文本等。
-
加载初始资源(这些资源您将立即在场景中需要,例如,如果您在房间内出生,则加载在房间内纹理以及该房间内的任何模型。这些资源可能会在您离开房间后释放。)如果您的场景足够小以装入整个场景所需的每个资源,则这些内容可能与上面的项目相同。
-
设置摄像机,初始视口以及视图和投影矩阵。
-
设置整个场景可能需要的Command Bundles。
4.更新游戏逻辑
这是游戏真正的核心部分。在这个阶段你可能会更新AI,检查来自网络的信息,更新场景中的对象信息,例如位置和动画。你懂的,
5.加载/释放资源
这是您的资源管理器进入的位置。如果对象进入的场景具有尚未加载的纹理,则可以在此处加载。如果有物体离开场景,也可以在此处卸载。如果愿意,可以将资源管理器放在单独的线程上。一种执行此操作的方法是,如果有对象进入场景,则游戏逻辑会通知资源管理器。当主循环继续时,资源管理器将开始加载所需的纹理。如果在绘制对象时尚未加载纹理,则资源管理器将提供临时或默认纹理。这对于具有开放世界的游戏很有用。与对象离开场景时一样,它使资源管理器(在单独的线程上)知道不需要哪些资源(通常是引用计数达到零),并在资源管理器释放资源时继续执行,而不是在主循环在继续之前等待资源管理器释放资源。
6.等待GPU
您很可能将使用双倍或三倍缓冲,这意味着您将至少拥有2-3个命令分配器。这样做的原因是因为在执行与其关联的命令列表时无法重置命令分配器(另一方面,使用命令队列执行命令后可以立即重置命令列表)。这意味着对于每个帧,在此阶段,就在重置命令分配器之前,您将检查GPU是否已完成与该命令分配器关联的命令列表。您将为此使用隔离和隔离事件。您还需要为每个帧设置隔离,并为每个线程需要一个隔离事件。在帧“f”上执行命令列表时,下一步是等待GPU在帧“f + 1”结束。对于三重缓冲,它将如下所示:
- wait for GPU to finish with frame 1
- render frame 1
- wait for GPU to finish with frame 2
- render frame 2
- wait for GPU to finish with frame 3
- render frame 3
- wait for GPU to finish with frame 1
- render frame 1
7.重置命令分配器和命令列表
在等待GPU完成要使用的命令分配器后,您将其重置以及重置命令列表。如果与前一帧相比绝对没有任何变化,则不必总是重置命令列表,但是几乎从来没有这种情况。如果您知道经常重复执行某些命令序列,请将它们放入Bundles中,然后在命令列表中执行bundes。
8.填充任务列表
这包括您希望GPU执行的大多数操作,例如绑定诸如顶点和索引缓冲区之类的资源,纹理,创建描述符,设置管线状态,使用资源屏障,设置隔离值等。
9.等待任务列表线程(如果是多线程的话)
如果您有多线程应用程序,则可能要在单独的线程上填充命令列表。一次只能有一个线程访问命令列表,因此每个线程将需要自己的命令列表,以及自己的隔离,隔离事件和命令分配器。您调用带有命令队列的执行命令列表数组,因此主线程将等待,直到命令列表线程完成其命令列表的填充。它将把命令列表放入数组中,并与命令队列一起执行。
10.执行任务列表
这是你在command queue调用ExecuteCommandLists()来渲染你场景的阶段。
Direct3D 12中的多线程(Multithreading in Direct3D 12)
我觉得我需要简短的概括一下利用多线程的应用程序的结构,因为这才是Direct3D 12真正的威力所在。
实际上很简单。它看起来像这样:
-
初始化应用程序(包括d3d和其他所有内容)
-
启动主循环
-
更新游戏逻辑
-
产生多个线程
-
每个线程等待GPU完成执行上一帧的命令列表
-
每个线程重置先前的帧命令分配器
-
每个线程重置其命令列表
-
每个线程填写其命令列表
-
主线程等待命令列表线程完成其命令列表的填写
-
使用完成的命令列表数组执行命令队列
-
转到3。
每个线程都有自己的命令列表
这是多线程应用程序变得有趣的地方。您需要以某种方式在逻辑上分割场景,以便每个线程可以填充部分场景的命令列表。有两种方法可以执行此操作,但是请记住,在执行命令列表时,将按照您在数组中提供命令的顺序执行它们。为了使应用程序获得最大性能,您一直想做的一件事就是按管线状态对实体进行分组。因此,如果场景中的两个对象使用特定的PSO,则需要尝试将它们放在一起,这样您只需为它们更改一次PSO。如果未将它们放在一起,则可能必须更改PSO两次,每个对象一次。但是,这并非总是将命令分组的最佳方法。由于诸如透明度之类的某些因素,您几乎总是需要从远到近绘制场景(对于相机来说)。如果共享同一PSO的那两个对象是窗户,一个窗户很远,并且一个窗户在摄像机前面,如果您将这两个对象共享在一起,因为它们共享了相同的PSO,则场景将错误的渲染。如果您先画出它们,则前面窗后将什么也不会出现。
要分组的第一件事很可能是距相机的距离。您可能有一个绘制远距离对象的命令列表,一个绘制近距离对象的命令列表,一个绘制天空盒的命令列表,一个绘制用户界面(例如健康状况)的命令列表状态以及用于帧后处理的另一个命令列表。
多线程中的命令分配器
命令分配器在任何时候都只能记录一个命令列表。这意味着对于每个线程,您必须有一个单独的命令列表。您无法在执行命令列表时重置命令分配器,这意味着对于每个帧缓冲区,您将需要一个命令分配器(双缓冲区需要两个,三缓冲区需要三个)。
由于上述原因,程序中的命令分配器的数量必须为:NumberOfThreads * NumberOfFrameBuffers
如果您的应用程序有2个线程来填充命令分配器,并且您正在使用三重缓冲,则将需要2 * 3 = 6个命令分配器。
 微信
微信 支付宝
支付宝