(译)Terrain Rendering in Far Cry 5
本文是对https://www.gdcvault.com/play/1025480/Terrain-Rendering-in-Far-Cry 进行的中文翻译,翻译动机是PPT涵括了ProjectS的GPU Driven系统所有功能模块,需要学习下工业流程
大纲
- 地形渲染:渲染地形,将部分转移到GPU管线中
- 基础知识
- GPU管线
- 着色:对上一步渲染的地形进行着色
- 悬崖着色:针对悬崖做的着色方案和优化
- 高级地形:将基础地形和其他几何结合
- 屏幕空间着色:在一个屏幕空间的Pass对地形进行着色
- 基于地形的特效:使用GPU上的地形数据来增强对其他资产的渲染,如树木、草和岩石
地形渲染
地形渲染基础
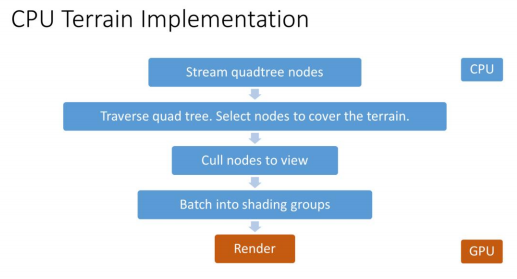
流程概述
一个简单且GPU友好的方式来渲染一个小区域的地形步骤如下:
首先渲染一个Mesh,作为地形的最小单位。

在VS中采样高度图,来改变顶点位置

使用一张albedo贴图在PS中进行着色,作为地形基础色

计算光照时再用一张normal贴图


使用四叉树来划分地形区域,整个世界构成item粒度从小到大依次为(LOD0):
- Patch(Tile):单个Grid,原分辨率
16*16,0.5m为单位 - Node:四叉树节点,由
8*8 = 64个Patch组成 - Sector:构成地形的区块,
64m*64m,在LOD0时,正好对应一个Node,对应64个Patch - World:整个地形,
160*160个Sector,共计10km*10km - Terrain Resolution:地形分辨率,以0.5m为单位来确定地形信息
但这数以百万计的Tile不能直接被渲染,否则性能太差了,所以需要LOD,我们把2km*2km的Tile作为最低的LOD等级(值越大,LOD等级越低,LOD5 < LOD0),依据地块距离玩家的距离进行LOD等级的递减,这样最终渲染的时候,只需要渲染几百个Tile即可

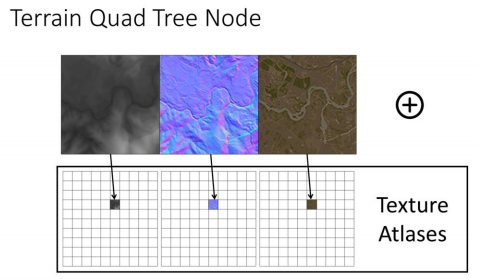
所以我们的世界是由成千上万个四叉树节点组成的。每个四叉树节点携带的信息如下:
- 高度图,R16_UNORM,
129x129 - 世界空间的法线图,可以认为z为正,并且同时把光滑度信息(smoothess)以及高光遮蔽信息(specular occlusion计算AO)压缩进去(PS:不太懂这是什么神奇原理),以获取更加写实的效果,BC3,
132x132 - Albedo基础色,使用1bit深度的Alpha通道,用于记录哪些地方被挖洞,BC1
132x132
当然还会存一些其他的贴图信息,稍后会讲解。
当我们加载一个四叉树节点时,这些贴图会被加载到Texture Altases(TextureArray)中,这意味着在知道所有四叉树节点的引用的贴图在Texture Atlases中的位置情况下, 我们可以得到所有贴图数据
下面是地形渲染的具体流程
- 对四叉树数据做流式传输
- 每帧遍历更新的四叉树,并选中合适的四叉树节点
- 在提交地形Patch组进行渲染之前,对每个视图的渲染阶段进行剔除和批处理
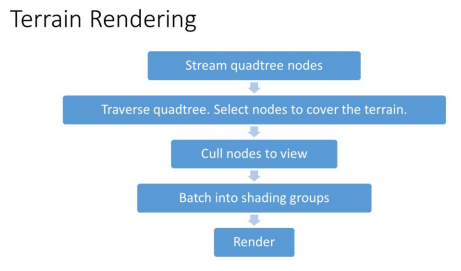
流式四叉树
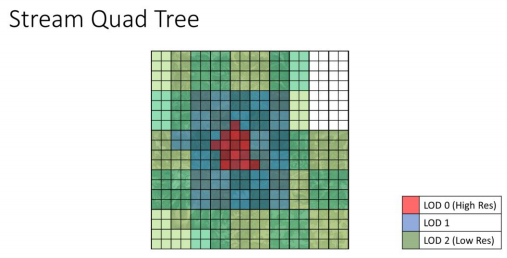
距离玩家最近的LOD等级最高,优先加载

下一个等级的LOD1覆盖范围将会是LOD0的两倍左右
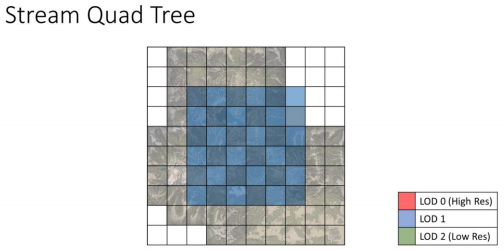
最低等级的LOD会覆盖整个地形,会保持常驻
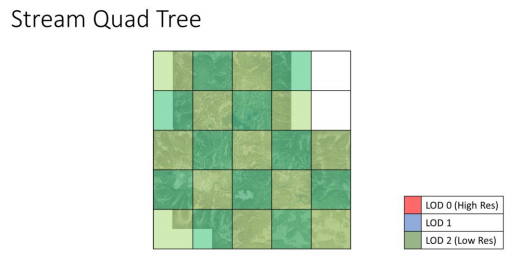
结合起来就象是这样
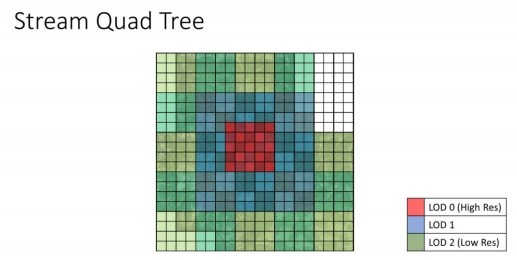
但是因为我们是流式异步传输的,所以任何节点的状态都可能是为完成的,所以在应用的时候可能会变成这样
为了方便演示,这里只演示了3级LOD,实际上FarCry5使用了6级LOD,也就对应6级四叉树节点
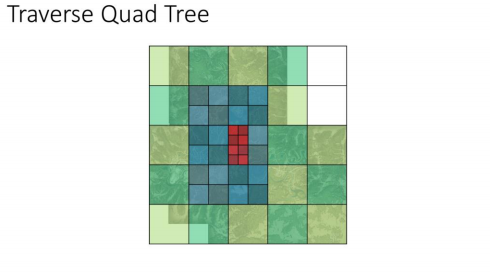
遍历四叉树
一个节点需要被渲染需要满足以下条件
从根节点遍历整个四叉树,并且当一个节点所有子节点都被加载,且想要增加这个节点的细节等级时,需要细分节点
如果按照上述规则处理的话,我们最终得到的四叉树是这样
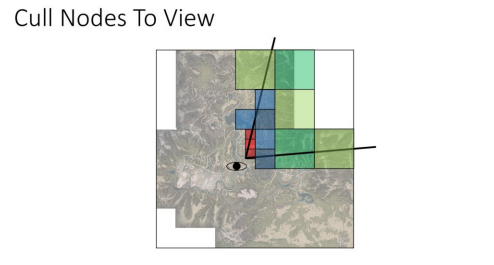
此外,我们只想渲染在相机内可见的节点,那么四叉树会变成这样
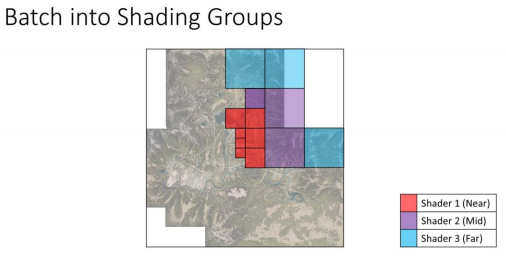
不同节点等级使用不同shader进行着色
GPU管线
上述流程很多部分可以让GPU去运算
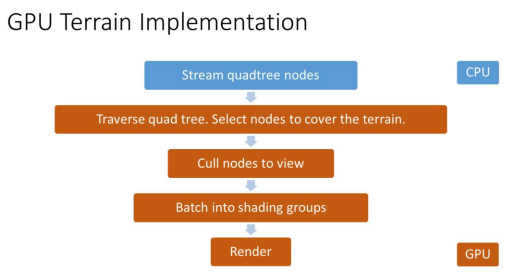
将这套流程转换到GPU的动机如下
- 这些数据只被GPU使用
- 减少CPU消耗
- 减少GPU消耗
- 因为可以通过四叉树提前完成最大程度的顶点剔除,从而避免可能的顶点带宽Bound,最终提高性能
- 在GPU数据结构中拥有很多地形数据的好处是,其余需要访问地形数据的模块会更加方便,例如GI,Instance(草,树,岩石等),Shader
但需要注意的是,我们在CPU端仍然有一些地形的数据结构,他被用于Gameplay,例如判断地形高度和材质查询
GPU数据结构
- 地形四叉树
- 常驻的,在加载/卸载节点的时候会进行更新
- 地形节点列表
- 这些节点产生于四叉树的遍历行为
- 每帧只Build一次
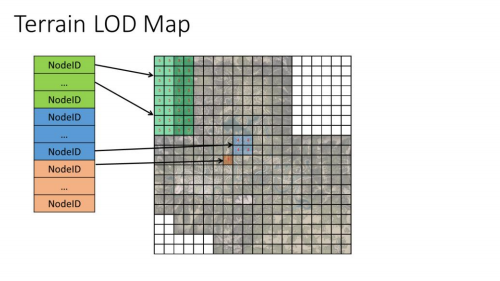
- 地形LOD Map
- LOD几何体被用于世界中每个Sector上
- 每帧从地形节点列表Build一次
- 可见的渲染Patch列表
- 裁剪后的节点列表,最终用于渲染
- 每帧Build一次
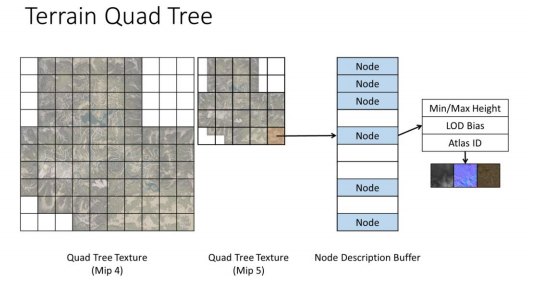
地形四叉树
地形四叉树模块由两个GPU对象构成
- 四叉树纹理,被手动mip用于索引四叉树节点(
PS:其实这倒不是必须的,只要有个机制能完成四叉树节点到Node Description Buff的映射即可) - NodeDescription Buffer,存储当前帧加载的节点
首先我们有一个手动分级(mipmap)的纹理,在Mip0是160x160的,并且6个四叉树节点等级都有一个不同的miplevel,这样一来,四叉树中每个节点都可以在这个纹理中找到对应纹素

这个纹理是16bit(UINT)深度的单通道的,用于索引NodeDescription Buffer中的节点,每个节点信息有最高,最低的地形高度,以及其使用的贴图Id
地形节点列表
即上一步提到的NodeDescription Buffer,是四叉树中所有节点的列表,其内容通过每帧遍历四叉树进行更新,可以通过Compute Shader计算每个LOD等级的节点信息,并进行填充
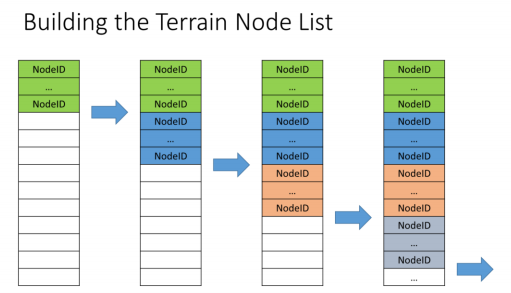
下面是具体的处理细节
先从最低级的LOD开始,把所有节点填充到一个Temp Buffer A中
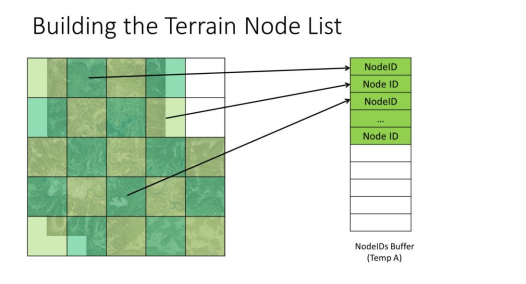
然后我们会对这些节点进行细分,读取原来的Temp Buffer A,并将其输出为两个Buffer,一个是Temp Buffer B,另一个是Final Result Buffer
对于Temp Buffer A中的每个节点,我们会判断其是否会被细分
- 如果会,我们将会将细分的子节点加入Temp Buffer B中
- 如果不会,则直接将节点加入Final Result Buffer

红框节点只有右上角的上级LOD被加载,所以不再进行细分,直接加入Final Result Buffer

红框节点所有节点都被加载了,加入细分列表,准备在下一次处理时进行更细粒度的细分
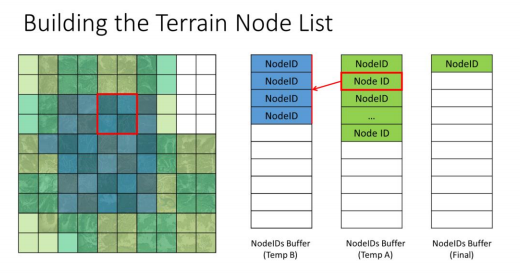
红框节点所有节点都被加载了,但我们决定不再继续细分它,因为它已经满足了需求,在Far Cry5中,这个标准是基于地块与相机的距离来处理的,此外,还会考虑每个节点的LOD偏差,来强制使一些地块使用更高级的LOD
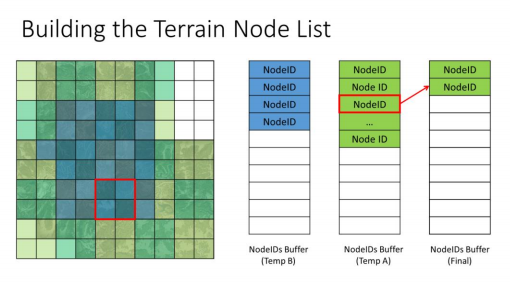
计算完成A缓冲区后,已经得到了两个额外的缓冲区数据,这些数据被用于后续的处理,下一步,我们会将B缓冲区和A缓冲区互换,随后再对B缓冲区进行计算
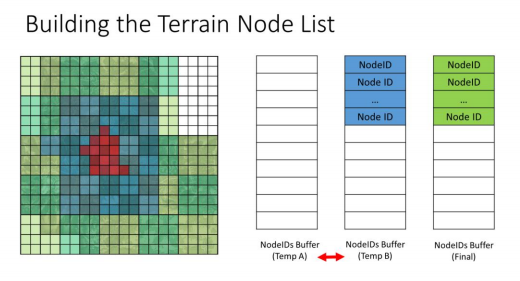
重复执行上述操作,即可得到Final Result Buffer
地形LOD Map
每帧都会完全填充一个8bit的RT,它包含了世界中每个Sector的LOD等级信息,我们需要这个信息,只为了一件事,那就是在不同LOD等级的Sector相接处进行缝隙修复,对于不存在地形的区域,存0即可
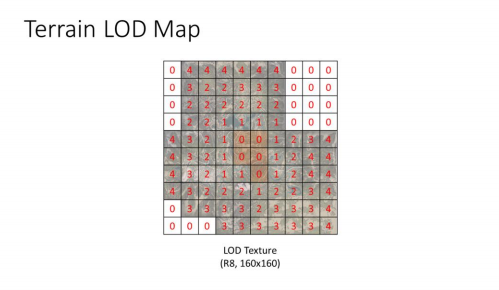
对于内容的填充,我们只需要遍历上一步的地形四叉树列表即可
在使用Compute Shader填充LOD Map时,需要使用Sector Count,而不是Node Count作为Thread Count,因为会造成大量数据在一个Thread中被填充,浪费了并行性。举个例子,因为基于NodeCount来处理,在最低级的LOD6上,每个Thread要写入2^6^2 = 32^2个值,而基于Sector Count,再通过地形节点列表拉取数据,可以让每个线程只写入1个数值即可
- Node Count作为Thread count,Thread数量少,单个Thread写入数据多
- Sector Count作为Thread count,Thread数量多,单个Thread写入数据少
可见的渲染Patch列表
它只是一个缓冲区,包含我们想要在DrawInstance中渲染的地形Patch列表。该缓冲区带有一个间接的args缓冲区来驱动绘制调用。Patch结构本身包含世界位置和大小,以及应该采样的地形四叉树纹理的地图集位置。每个Patch都将被渲染为一个16x16的网格(但网格分辨率会根据LOD等级不同而不同,例如LOD0是0.5m,LOD1是1m)。我们将通过获取地形节点列表中的所有四叉树节点来创建Patch列表,将它们分解成更小的Patch,并剔除我们不需要渲染的Patch。
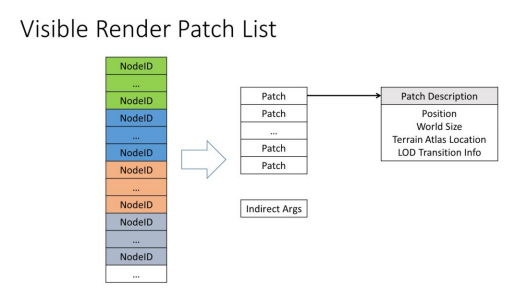
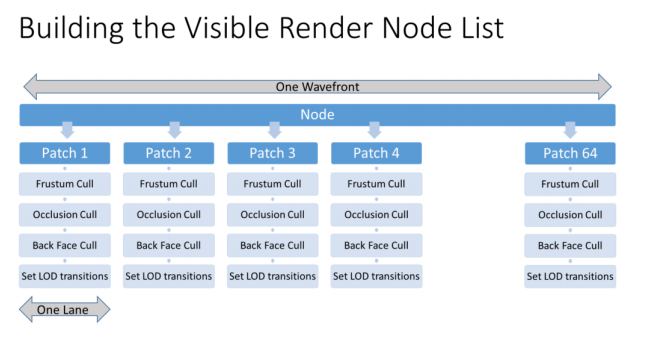
每个节点被细分为8x8个Patch,每个Patch可以当成一个16x16的grids进行渲染,对于每个Patch,我们需要进行以下操作
- 相机视锥体剔除
- 可见性遮蔽剔除
- 背面剔除
- 计算并打包LOD数据到Patch Data
GPU Culling
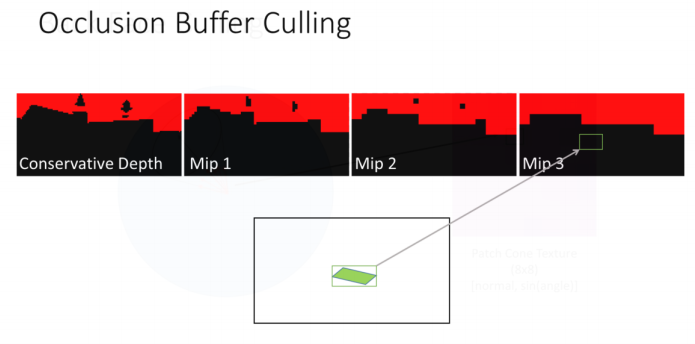
遵循Advances in Real-TimeRendering in Games的做法,使用子分辨率的保守深度缓冲区来对地形几何进行裁剪,生成深度缓冲区的不同miplevel,用以不同大小的对象对比深度
在剔除Pass里,我们会做以下操作
- 获取地形Patch包围盒
- 找到他们在屏幕上的投影区域
- 在mip中找到一个或多个覆盖了此区域的
- 进行深度测试并保守剔除
背面剔除
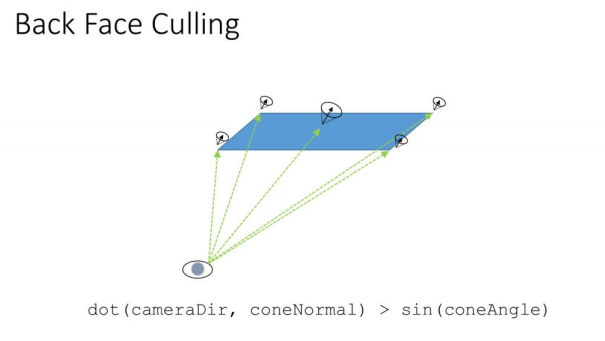
接下来,我们将删除任何可以被背面剔除的Patch,因为它们所有的面背对摄像机,没有被渲染的必要。
这要求我们在离线数据构建步骤中构建和存储关于每个Patch的信息。在这个离线步骤中,我们找到一个Patch中每个三角形的世界空间法线。然后我们找到一个球体上包含所有这些法线的最小圆,我们可以把它想象成一个圆锥。我们将一个节点中每个8x8 Patch的锥体存储为8x8纹理的texel。纹理在锥体的中心保持法线,以及由锥体对应的半角。参见寻找法线的最小边界球。我们使用BC3纹理来存储法线和角度。法线存储在两个颜色通道中,而sin(角度)存储在alpha通道中。这可能会导致精度问题,所以我们必须允许一些不利因素进行保守测试。
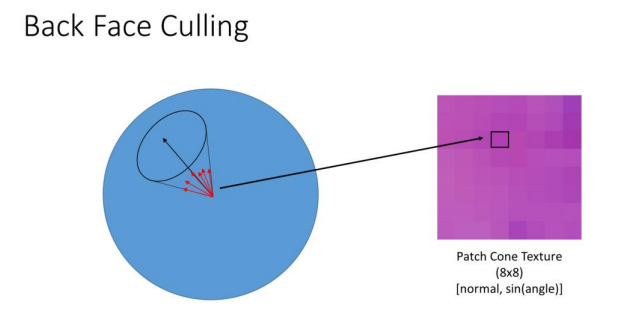
在运行时,我们对Patch锥纹理贴图进行采样,并对摄像机方向进行测试,看看是否可以剔除补丁。请参见[Shirmun]关于此技术的原始描述。不幸的是,它没有想象的仅仅是一个dot计算那么简单,因为相机锥体投射出的射线在整个Patch中都不同。为了保守一些,我们需要根据相机的方向检查到Patch的边界框的每个角落
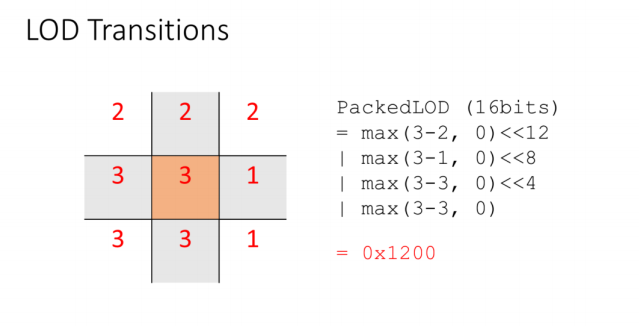
LOD转换
每个Patch都存储一个打包的LOD信息。是16位的:对于4个方向,每个方向用4个bit来标识LOD差值
在Culling过程中,我们通过采样每个Patch周围的LOD图来填充这个值。此值稍后将在顶点着色器中读取,以缝合网格。
例如,这里我们看到一个Patch,它位于角落或LOD发生变化的Sector。我们上面的LOD delta为1。右边的LOD delta为2。左边和下面可能在同一个Sector中,所以没有LOD差值
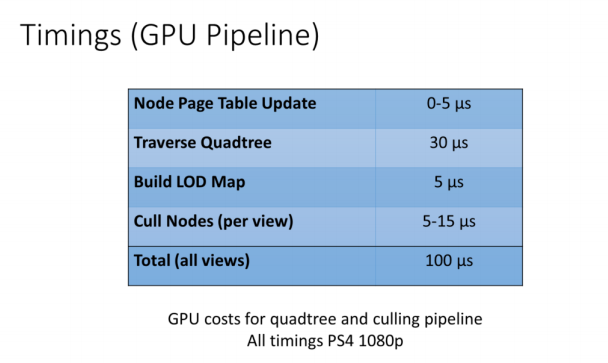
整个GPU管线耗时
顶点着色
我们使用一个DrawInstancedIndirect来渲染这些Patch,顶点的位置来自Patch信息,顶点高度来自高度图采样,我们需要处理mesh接缝以及挖洞情况
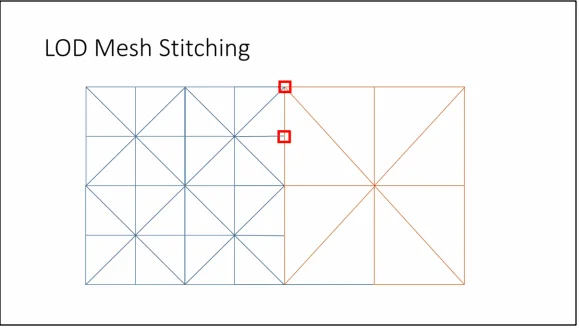
LOD Mesh接缝
当两个相邻的Patch位于不同LOD的Node中时,我们需要确保所有顶点都进行缝合,这样就不会看到不同LOD之间的接缝问题了
通过读取在筛选过程中创建的LOD打包数据,我们知道一个补丁连接到较低LOD补丁。在顶点着色器中,我们可以简单地将Patch边缘的顶点变形为所需的细分级别上最近的顶点。这里我们看到一个LOD偏差,所以我们焊接每对顶点。
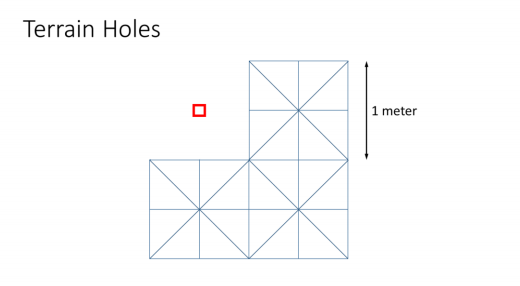
地形孔洞
我们保存地形空洞到一个1bit的BC1 alpha albedo贴图上
我们可以使用在投影位置返回NaN的技巧,在顶点着色器中挑选顶点。输出投影位置的NaN并没有在图形api中特别记录,但所有的GPU硬件似乎都支持这一点。与使用像素着色器丢弃或为带有孔的Patch构建独特的几何图形相比,这是非常简单和廉价的。

剔除一个顶点将会同时剔除与其相连的顶点,这使得一个孔的分辨率只能是地形分辨率的一半。但是我们的平面设计师可以在他们的半米地形上开1米的洞。
着色
地形着色
地形有了,现在我们该对它进行着色了,幽灵荒野行动GDC,这里会做一个简短的总结
请记住,每个四叉树节点都携带一个纹理索引。我们已经提及了高度图,法线图,Albedo。还有:
- Patch Cone纹理(用于我们前面提及的背面剔除)
- Color modulation纹理
- Splat图
正如我提到的,这些纹理在运行时都被加载到图集中。完整格式细节是:
- 高度图(R16_UNORM,129x129)
- 世界空间法线图(我们可以假设正z也包平滑和镜面遮挡)(BC3 132x132)
- Albedo图(BC1 132x132)
- Color modulation(BC1 132x132)
- Splat图(R8_UNORM 65x65)
- Patch Cone(BC3 8x8)

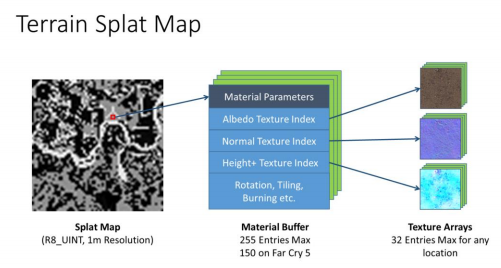
远的着色可以直接使用Albedo图/法线图。对于近处的着色,我们需要使用splat映射。
这个splat纹理是一个8位格式的纹理,索引了我们绘制到世界中的地表材质
splat纹理可以引用256种材质,尽管在《孤岛惊魂5》上,我们实际上只有~150的地形材质。
材质包含对存储在纹理数组中的一组细节纹理的索引。我们有3个典型的PBR纹理类型的数组,并且纹理是动态流式的,因为它们是被splat映射引用的。
该材质还包含一组参数,定义方向/瓷砖/地形是否可以燃烧等。
细节纹理的分辨率:
- Albedo(BC1,1024x1024)
- 法线/平滑度/镜面遮挡(BC3,1024x1024)
- 高度/颜色Mask(BC1,512x512)
注意,由于内存限制,每个细节纹理类型中只有32个可以一次加载到内存中(~70MB的内存)。四叉树引用的纹理的流由我们的流依赖系统处理。但是世界建设团队必须小心地管理每个生物群落的材质,以保持在他们的32个纹理预算之内。
当我们想渲染一个地形像素时
- 获取像素在Tile中的本地坐标。
- 使用它来查找splat纹理,以得到我们的材质ID。
- 使用材质ID获取材质描述(其中包括要采样的详细纹理)。
- 我们使用基于世界坐标的材质平铺和旋转的uv来采样相关的细节纹理。
- 这为我们提供了我们可以用于着色的最终材质数据。

然而,我们的地形位置可能会映射到4个splat纹素的某些点。所以我们需要采样的不是1个,而是4个周围的材质。我们使用由材质的高度进行双线性系数修正在Shader中混合了4个结果,即:
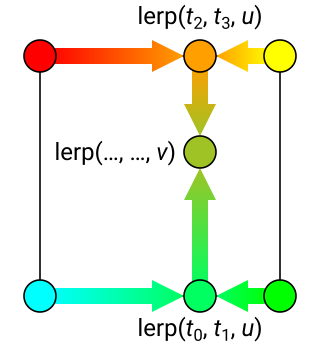
这意味着每个地形像素需要采样16个纹理,以计算最终的材质结果。
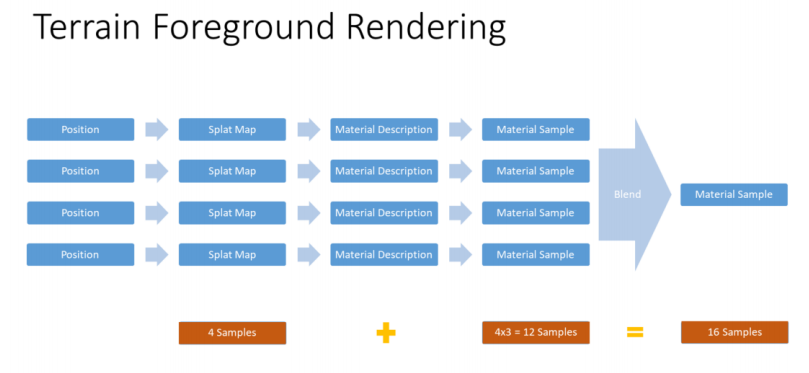
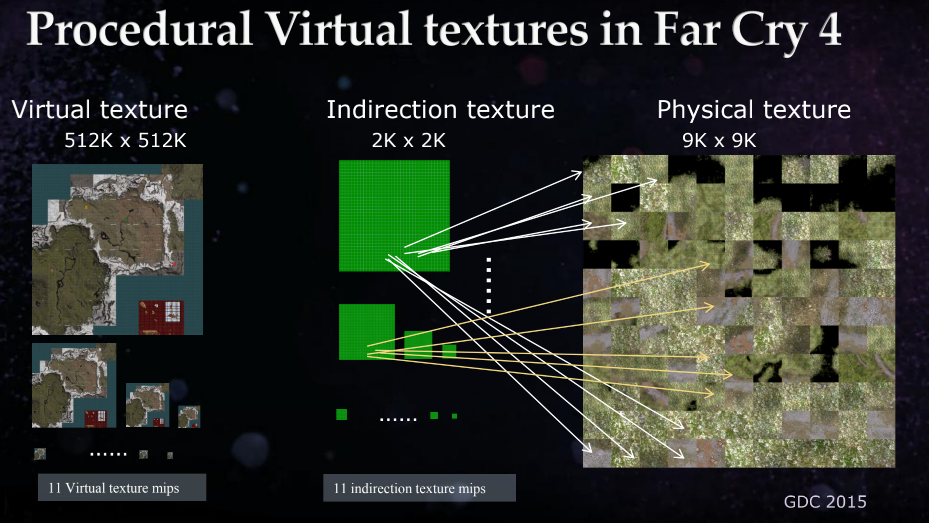
Virtual Texturing
我们可以看到,基于splat映射进行的材质采样是昂贵的。我们可以通过将结果缓存到一个虚拟纹理中来节省一些性能。我们的地形虚拟纹理系统在GDC 2015的Far Cry 4自适应虚拟纹理演示中描述过
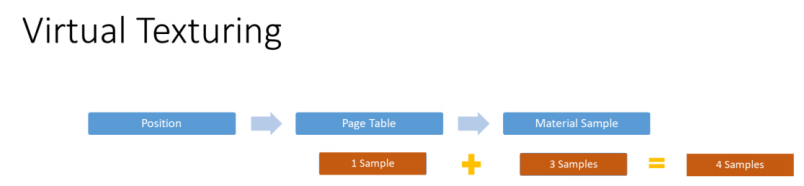
虚拟纹理允许我们模拟覆盖了地形的极大的纹理。我们只存储在当前时间需要采样的纹理部分。缓存的纹理数据被存储在物理纹理中的Pages中。如果我们想在一个位置获得地形材质,我们首先在Page Table纹理中查找相应的位置。会返回物理纹理的Page。然后我们对物理纹理进行采样获取最终结果。

这让我们只需要进行4次采样即可完成地形纹素的着色
虚拟纹理Page渲染
- 通过Splat纹理进行这些被缓存的纹理Page渲染
- 我们每帧渲染6个虚拟纹理Page
- 1Page = 256x256纹素 + 4纹素边框
- 利用Compute Shader将其压缩为BC格式
- 2xBC1(Albedo/Smoothness/Specular Occlusion)
- 1xBC3(法线贴图)
- 当渲染下一个Page时,将会异步计算压缩过程
- GPU耗时每帧需要控制在1ms内
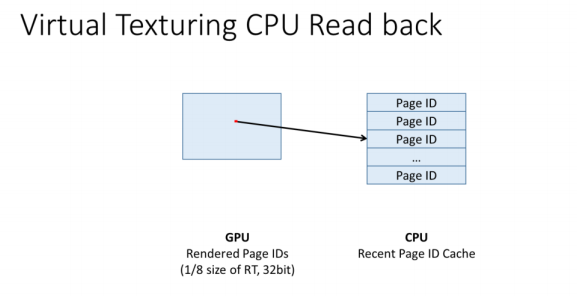
我们总是需要跟踪需要更新的纹理Page。所以当我们渲染地形时,我们也会把请求的页面写给一个绑定的UAV。
然后,我们读取CPU上请求的页面,以确定下一个要呈现的页面的优先级。
UAV是1/8大小的RT,以保持CPU读回成本低。我们在64帧里抖动屏幕空间的采样位置,以确保我们随着时间的推移收集所有渲染的Page id。
由于我们使用虚拟纹理,我们可以以很少的额外成本合成多层道路和贴花。您可以在这个屏幕截图中看到可视化的结果。道路贴花在地形纹理上渲染,还有一些其他的贴花效果


 微信
微信 支付宝
支付宝