AI GC与游戏行业野望
前言
最近 AI 用得越多,我越觉得自己不能只停留在“会问问题”这一层。
AIGC、AI Agent、MCP、Skills 这些词天天飞,听多了很容易糊成一团。遂有此文:先把 2017 年 Transformer 之后,到现在 2026 年这条线上的关键概念捋一遍,再聊聊它可能怎么撞进游戏行业。
首先,什么是 AI GC?简单来说,AIGC 是指利用人工智能技术(尤其是生成式大模型),通过接收自然语言指令(Prompt)或其他模态的输入,自动或半自动地生成文本、图像、音频、视频、3D 模型甚至代码等数字化内容的一种新型生产方式。
1. 从内容生产的演进史定义:生产力的跨越
理解 AIGC,最好的参照物是 PGC 和 UGC:
-
PGC (Professionally Generated Content,专业生成内容): 门槛高、产能低、质量高。比如专业工作室开发 3A 大作、好莱坞团队拍摄电影。
-
UGC (User Generated Content,用户生成内容): 门槛低、产能高、质量参差不齐。比如玩家用地图编辑器做自定义关卡、普通用户在平台发布 Vlog。
-
AIGC: 是 PGC 和 UGC 的结合体与升维。它将生产门槛降到了最低(只需输入提示词或意图),同时又具备逼近甚至超越人类专业水平的产能和质量。它打破了以往“高质量”与“高产量”不可兼得的物理常识。
2. 从技术底层定义:生成式 AI 的具象化产物
AIGC 本身并不是一个底层的技术名词,而是一个产业端/应用端的概念。它的技术底座是 Generative AI(生成式 AI)。
过去的 AI 主要是“分析型”或“决策型”的(例如人脸识别、推荐算法、自动化寻路),它们旨在寻找规律。而目前的 AIGC 是基于以下核心架构的“创造型”系统:
-
Transformer 架构: 撑起了大语言模型(LLM),赋予了 AI 理解逻辑、生成复杂文本和编写代码的能力。
-
Diffusion(扩散)模型: 主导了视觉领域,负责将高维噪声一步步还原为极具细节的图像和视频。
-
多模态大模型 (Multimodal Models): 正在打通上述感官壁垒,实现 Text-to-Image(文生图)、Text-to-Video(文生视频)、Audio-to-Face(音频驱动面部)等跨模态的连贯生成。
3. 从模态与应用边界定义:全维度的数字化重塑
AIGC 的定义随着其能生成的内容模态(Modalities)在不断扩展,它覆盖了几乎所有人类感知信息的媒介:
-
文本生成 (Text): 剧本创作、代码编写、多语种翻译、逻辑梳理。
-
视觉生成 (Image/Video): 概念设计、原画生成、高保真视频流生成、材质贴图无缝生成。
-
音频生成 (Audio): 音乐编曲、逼真的 TTS(文本转语音)、环境音效生成。
-
空间生成 (3D): 文本生成 3D 模型、基于 NeRF(神经辐射场)或 3DGS(3D高斯溅射)的物理场景快速重建。
一句话总结: AIGC 不是某一个软件,也不是单一算法。对我来说,它更像一种新的内容生产方式:以大模型为核心大脑,以自然语言和多模态输入为交互界面,把文本、图像、音频、视频、3D、代码这些数字内容的生产成本继续往下压。
现在我们的工作已经和 AI 紧密绑在一起了。只知道 AI 编程很好用,但完全不知道 LLM 内部怎么回事,就有点像拿着一把神兵乱砍:爽是爽,翻车的时候也是真的疼。所以还是先从深度学习这些基础概念看起,多少知道一点底层原理,后面用 AI 才不至于全靠玄学。
大语言模型(LLM:Large Language Model)
基础概念
1. 核心概念解读
机器学习 (Machine Learning, ML)
- 含义:人工智能的一个子领域。它的核心思想是:不直接编写程序来解决问题,而是让计算机通过“学习”数据中的模式,自己找到解决方案。
- 关键:“学习”意味着模型会通过数据自动调整其内部的参数,从而提升在特定任务(如预测、分类)上的性能。
- 比喻:教孩子识别猫。你不是给他一套严格的规则(比如有胡子、尖耳朵),而是给他看成千上万张猫和狗的图片,让他自己总结出猫的特征。
神经网络 (Neural Network, NN)
- 含义:一种模仿人脑神经元连接方式的计算模型,是实现机器学习的一种方法/算法。
- 结构:由大量相互连接的“神经元”(节点)组成。每个神经元接收输入,进行简单计算,然后产生输出并传递给下一层神经元。
- 关键:通过调整神经元之间的连接强度(权重)来学习。
- 比喻:一个复杂的投票系统。初级神经元(输入层)负责看图片的各个像素(是黑色吗?是边缘吗?),中间神经元(隐藏层)综合这些初级信息(看起来像眼睛?像胡须?),最后层的神经元(输出层)根据所有信息投票决定这是不是一只猫。
深度学习 (Deep Learning, DL)
- 含义:机器学习的子领域,特指使用“深度”神经网络的技术。“深度”指的是神经网络中具有很多层(通常超过3层) 隐藏层。
- 关键:层数越多,网络能学习到的特征就越抽象和复杂。浅层网络可能识别边缘、颜色,深层网络就能识别眼睛、轮子,甚至整个物体和场景。
- 关系:深度学习 ⊂ 机器学习 ⊂ 人工智能
- 比喻:如果说传统机器学习是手工雕刻,那么深度学习就是使用大型机械化工具进行雕刻,能处理更复杂、更庞大的原材料(数据)。
大语言模型 (Large Language Model, LLM)
- 含义:一种基于深度学习(具体是Transformer架构)的、经过海量文本数据训练的巨大神经网络。它的核心任务是理解和生成人类语言。
- 关键:
- 大 (Large):参数量极其巨大(通常达数十亿、数千亿),模型规模大,训练数据量也巨大。
- 语言模型 (Language Model):它的本质是预测下一个词的概率。给定一句话的前几个词,它能计算出下一个最可能出现的词是什么。通过这种反复预测,它就能生成流畅的句子、段落甚至文章。
- 著名例子:ChatGPT(基于GPT系列)、Gemini(基于PaLM)、LLaMA、文心一言等。
- 比喻:一个阅读了互联网上几乎所有书籍、文章、代码的“超级大脑”。它学到了语法、事实、逻辑推理甚至不同文风。当你给它一个提示(Prompt),它就在基于这个“大脑”中的所有知识,进行一场极其复杂的“词语接龙”。
2. 联系与区别
联系(层次关系)
这是一个典型的从属关系,就像“俄罗斯套娃”:
- 人工智能 (AI) 是最广阔的领域,目标是让机器智能地行动。
- 机器学习 (ML) 是实现AI的一种核心途径。
- 深度学习 (DL) 是机器学习中目前最强大、最热门的一个分支。
- 神经网络 (NN) 是深度学习(及部分机器学习)的基础架构。
- 大语言模型 (LLM) 是深度学习技术(特别是Transformer)在自然语言处理(NLP)领域的一个具体应用和辉煌成果。
人工智能 > 机器学习 > 深度学习 > (神经网络) > 大语言模型
区别(对比总结)
| 术语 | 核心定位 | 关系比喻 | 主要解决的任务 |
|---|---|---|---|
| 机器学习 (ML) | 一个领域/方法论 | “父类” | 预测、分类、聚类等(如图片分类、股票预测) |
| 神经网络 (NN) | 一种算法/架构 | ML的一种“工具” | 适合处理图像、语音、文本等复杂非线性问题 |
| 深度学习 (DL) | ML的一个分支 | “使用了高级工具的ML” | 计算机视觉、语音识别、自然语言处理等 |
| 大语言模型 (LLM) | DL的一个具体应用 | “DL领域里的一个明星产品” | 理解和生成人类语言(如对话、翻译、摘要) |
总结一张图
graph TD
A[人工智能 AI] --> B[机器学习 ML];
B --> C[深度学习 DL];
C --> D[大语言模型 LLM];
C -.-> E[其他深度学习应用<br>如:图像识别、自动驾驶];
B -.-> F[其他机器学习算法<br>如:随机森林、SVM];
subgraph "核心技术"
G[神经网络 NN]
end
C --> G;
D --> G;模型训练流程
训练和推理使用的是完全相同的 Transformer 架构,区别只在于:
- 训练时权重是可变的,需要反向传播更新
- 推理时权重是固定的,只做前向传播
flowchart TD
subgraph SharedArch ["🔷 Transformer 核心架构"]
direction TB
SA1["词嵌入 + 位置编码"]
SA2["线性投影生成 Q, K, V"]
SA3["自注意力机制 Self-Attention"]
SA4["前馈神经网络 FFN"]
SA5["输出层 → Logits"]
SA1 --> SA2 --> SA3 --> SA4 --> SA5
end
subgraph Training ["第一部分:训练阶段 Training"]
direction TB
T1["1️⃣ 准备海量文本<br>切分Token,遮挡下文"]
T2["2️⃣ 初始化权重<br>Q,K,V,FFN 随机值"]
subgraph TrainLoop ["🔄 训练循环(数十亿次)"]
direction TB
T3["3️⃣ 前向传播 ⬇️<br>数据正向流经 Transformer"]
T4["4️⃣ 计算损失 Loss"]
T5["5️⃣ 反向传播 ⬆️<br>梯度逆向流经 Transformer"]
T6["6️⃣ 更新权重<br>梯度下降优化参数"]
T3 --> T4 --> T5 --> T6
T6 --> T3
end
T1 --> T2 --> TrainLoop
end
subgraph Inference ["第二部分:推理阶段 Inference"]
direction TB
I1(["📝 用户输入"])
I2["前向传播 ⬇️<br>数据正向流经 Transformer"]
Limit1{{"⚠️ 上下文窗口限制"}}
I3["采样生成下一个词"]
I4(["🎯 输出 Token"])
I1 --> I2
I2 -.-> Limit1
I2 --> I3 --> I4
I4 -- "拼接继续" --> I1
end
TrainEnd(["🎉 训练完成<br>权重固定"])
T3 -.-> |"正向穿过"| SharedArch
T5 -.-> |"逆向穿过<br>计算梯度"| SharedArch
I2 -.-> |"正向穿过<br>(仅此,无反向)"| SharedArch
Training --> TrainEnd
TrainEnd -. "加载权重" .-> Inference
classDef archStyle fill:#fff3e0,stroke:#ff9800,stroke-width:2px,color:#333
classDef loopStyle fill:#c8e6c9,stroke:#388e3c,stroke-width:2px,color:#333
classDef highlight fill:#fce4ec,stroke:#e91e63,stroke-width:2px,color:#333
class SharedArch archStyle
class TrainLoop loopStyle
class Limit1 highlight
大模型的训练,本质上是一个**“从随机瞎猜到精准预测”的纠错过程**。我们可以把这个过程拆解为以下几个核心步骤。为了方便理解,我们以最基础的**“预训练”(Pre-training,也就是文字接龙)**为例:
1. 准备数据(构建考卷)
大模型并不会像数据库那样把文章“存”起来。在训练前,我们需要把海量的文本(比如维基百科、网页、书籍)切分成 Token(词元)。
然后,我们用一种极其简单粗暴的方式制造“考题”:遮挡下一个词,让模型猜。
假设有一句话:“人工智能改变了世界”。
- 输入: “人工” -> 目标答案: “智能”
- 输入: “人工智能” -> 目标答案: “改变”
- 输入: “人工智能改变” -> 目标答案: “了”
2. 初始化(一堆废铁)
在模型还没开始训练时,它内部所有的权重矩阵(包括你提到的 ,以及前馈神经网络的参数),里面装的全都是随机生成的毫无意义的数字。
这时候如果你让它接着“人工智能”往下写,它输出的可能是“苹果”、“沙发”或者一堆乱码。
3. 前向传播(盲目作答)
我们将一句话(比如“人工智能”)输入模型。这些 Token 转化为向量后,开始在这个庞大的网络里穿梭:乘上随机的 QKV 矩阵,经过自注意力机制,穿过前馈神经网络……
最后,模型会在它的词表中(假设有 10 万个词)输出一个概率分布。因为此时矩阵是随机的,所以它可能是这么猜的:
- “苹果”:15%
- “吃饭”:10%
- ……
- “智能”:0.001%
4. 计算损失(打分与错题本)
系统会拿着模型的预测概率,去和“正确答案”进行对比。
正确答案是“智能”,但模型只给了它 0.001% 的概率。系统会通过一个叫做交叉熵损失函数(Cross-Entropy Loss)的数学公式,计算出一个Loss(损失值/误差)。
Loss 越大,说明模型错得越离谱。训练的终极目标,就是要把这个 Loss 降到最低。
5. 反向传播(追责与复盘)—— 核心魔法!
这是大模型能够“学习”的最关键一步。模型知道自己错了,但它内部有成百上千亿个参数,到底是谁导致了错误?
这就是反向传播(Backpropagation)算法的工作。它运用微积分中的链式法则(Chain Rule),从最后的误差开始,一层一层往回倒推,计算出每一个参数(每一个矩阵里的每一个数字)对这个巨大的误差“负有多大责任”。这个责任值,在数学上被称为梯度(Gradient)。
比如,系统发现:如果把 矩阵第一行第一列的那个数字稍微调大一点点,预测“智能”的概率就会上升。那么这个方向就是它的梯度。
6. 权重更新(知错就改)
找准了每个参数应该调整的方向后,模型就会使用**优化器(Optimizer,比如 AdamW)来修改这些参数。 数学表达上,这就是著名的梯度下降(Gradient Descent)**公式:
(新的权重 = 旧的权重 - 学习率 误差对该权重的梯度)
循环往复(炼丹过程)
模型会对海量的数据,成千上万次地重复步骤 3 到 6:
读数据 -> 瞎猜 -> 算误差 -> 找原因 -> 微调参数 -> 再读下一条数据……
这就是为什么训练大模型需要成千上万张昂贵的 GPU(比如你之前关注过的算力设备和 RTX 5080 虽然是推理端,但训练端需要 H100 级别的集群)连续运行几个月的原因。所有的算力,都在疯狂地做矩阵乘法(前向传播)和求导更新(反向传播)。
当它看过了几万亿个词,内部的矩阵被微调了无数次之后,那些原本随机的数字,就变成了一组极其精妙的规律组合。这时, 就真正学会了如何提取人类语言中的上下文关系。
所以,“训练”并不是在往模型里塞数据,而是用数据去打磨模型内部那些矩阵的数值,让它形成一种类似人类“直觉”的数学表达。
你可以把整个过程想象成盲人摸象式地调音效台:有 700 亿个旋钮(参数),每次放一首歌(数据),如果不好听(Loss 高),就计算出每个旋钮该往左还是往右稍微拧一点点,直到放什么歌都好听为止。
Transformer架构
- 必读论文(精读):
- 《Attention Is All You Need》:所有一切的起点。重点关注自注意力机制如何实现“全局依赖关系建模”。推荐3Blue的视频讲解,通俗易懂
- 《LLaMA: Open and Efficient Foundation Language Models》:了解如何从零开始高效地训练一个现代LLM,包括技术细节如
RMSNorm,SwiGLU,RoPE等。这比读GPT-3的论文更贴近开源实践。
- 核心学习资源:
- 博客:再次推荐Jay Alammar的 《The Illustrated Transformer》
- 视频:YouTube上搜索“Transformer详解”,找一些有公式和代码推导的视频,你会很快抓住精髓。
我们可以尽量避开那些复杂的数学公式,把它想象成一个超级高效的“阅读与写作团队”。
Transformer 就是目前所有主流大语言模型(LLM,比如 ChatGPT,Gemini,Claude)的“发动机”。它之所以能一战成名,主要是因为它解决了以前 AI 看文章时“看后面忘前面”以及“阅读速度太慢”的问题。
我们可以把它的核心逻辑拆解成以下几个关键部分:
1. 词向量化 (Embeddings):给文字发“身份证”
AI 是看不懂人类文字的,它只懂数字。所以第一步,Transformer 会把一句话里的每一个词,转化成一串长长的数字。
- 通俗理解: 就像是给每个词发了一张带有无数个标签的“身份证”。比如“苹果”,身份证上可能会标记:水果属性(0.9)、科技公司属性(0.8)、红色属性(0.7)。这样 AI 就能通过算数字,知道“苹果”和“梨”关系近,和“石头”关系远。
2. 自注意力机制 (Self-Attention):阅读时的“划重点大师”
这是 Transformer 最伟大、最核心的发明!以前的 AI 看句子是一个词一个词按顺序看,很容易看了后面忘了前面。而“自注意力机制”让 AI 可以同时看着一句话里的所有词,并找出它们之间的内在联系。
-
通俗理解: 假设有一句话:“苹果公司今年发布了新的苹果手机,我想吃个苹果庆祝一下。”
-
当 AI 读到第一个“苹果”时,它的“注意力”会瞬间扫过全句,发现后面跟着“公司”和“手机”,于是它立刻明白这个“苹果”是科技品牌。
-
当它读到最后一个“苹果”时,它发现前面有“吃”字,就知道这回指的是真水果。它能精准地给句子里的不同词汇分配“注意力(权重)”。
3. 并行计算 (Parallel Processing):全员加速的“流水线”
在 Transformer 出现之前的模型(比如 RNN),必须等第一个词处理完,才能处理第二个词,像单行道一样,效率极低。
- 通俗理解: Transformer 打破了这种限制。它雇佣了一个极其庞大的团队,可以同时处理一整篇文章里的所有词汇。这就好比以前是一个人把一本书从头读到尾,现在是一万个人同时看这本书的不同部分,看完瞬间在大脑里汇总。这也是为什么大模型能用海量数据进行快速训练的原因。
4. 编码器与解码器 (Encoder & Decoder):理解与创作的闭环
标准的 Transformer 架构由两部分组成(虽然像 GPT 系列后来主要只用了“解码器”,但概念是相通的):
-
编码器 (Encoder) - “超级阅读理解家”: 负责把用户输入的话彻底读懂,提取出所有的关键信息和上下文联系。
-
解码器 (Decoder) - “超级打字员”: 拿着编码器整理好的理解报告,开始根据上下文,预测下一个最应该输出的词是什么,一个词一个词地把回答“蹦”出来。
总结一下:
Transformer 就像是一个拥有**“一目十行(并行计算)”且能“精准抓取上下文重点(自注意力机制)”**的超级大脑。它不再死板地逐字翻译,而是真正开始理解词与词在特定语境下的关系。
FAQ
各种不同的大语言模型之所以不同,在编码和解码阶段用的Q,K,V矩阵不同?因为这些矩阵就是大模型自己训练出来的?
基本是正确的,但它只涵盖了大模型差异的其中一部分。
简单来说:是的,不同的大模型在编码和解码时使用的 Q、K、V 权重矩阵是完全不同的,而且这些矩阵里的具体数值,就是模型在海量数据中“自己训练(学习)”出来的结果。
不过,要全面理解不同大模型的差异,我们需要把视角放大一点。以下是决定各种大模型之所以不同的关键因素:
1. 核心权重差异:不仅是 Q, K, V
在 Transformer 架构中,自注意力机制(Self-Attention)负责让模型理解词与词之间的上下文关系。
- 权重矩阵 : 文本输入模型后,会乘上这三个线性投影矩阵,生成对应的 Q(查询)、K(键)和 V(值)。模型在预训练阶段不断通过反向传播调整的,正是这些矩阵里的参数。不同模型(比如 Llama 3 和 GPT-4),它们经过不同的数据和时间训练,这几个矩阵里的数值截然不同,导致它们对同一句话的“注意力重点”完全不一样。
- 前馈神经网络(FFN / MLP)矩阵: 在注意力层之后,还有一个全连接层。如果说 Q, K, V 决定了模型如何理解上下文关系,那么 FFN 层的权重矩阵则被认为是模型存储事实性知识(比如“法国的首都是巴黎”)的地方。FFN 层的参数量通常比注意力层还要大,这部分的权重不同,也是模型差异的巨大来源。
2. 架构设计的差异(骨架不同)
即使都是 Transformer 架构,不同公司在设计时也会做很多不同的选择:
- 参数规模与层数: 比如 7B(70亿参数)和 70B 的模型。参数更多意味着 Q, K, V 矩阵的维度更大,Transformer 的层数(Blocks)堆叠得更多。
- 注意力机制的变体: 为了提高推理速度或降低显存占用,不同的模型会采用不同的注意力机制。比如标准的多头注意力(MHA),或者现在开源模型常用的分组查询注意力(GQA)和多查询注意力(MQA)。这直接改变了 K 和 V 矩阵的数量和结构。
- 混合专家架构(MoE): 像 Mixtral 或 DeepSeek 采用的架构,里面有多个不同的 FFN 专家网络,每次只激活其中一部分,这与传统的稠密(Dense)模型在结构上有着根本区别。
3. 训练数据(灵魂不同)
这是导致模型表现差异最核心的因素。即使两个模型使用了完全一模一样的网络架构和初始代码,只要喂给它们的训练语料不同,最终训练出来的 Q, K, V 矩阵以及所有参数都会完全不同。模型读过的书、看过的代码和多语言语料的比例,直接决定了它的能力边界。
4. 训练阶段与对齐策略(性格不同)
- 预训练(Pre-training): 此时模型只学会了“接话把儿”(文字接龙)。
- 指令微调(SFT)与人类反馈强化学习(RLHF): 这个阶段决定了模型是一个胡言乱语的文本生成器,还是一个懂礼貌、能按照指令回答问题的 AI 助手。各个厂商的对齐算法和微调数据质量,决定了模型最终的“性格”和逻辑推理能力。
总结来说,Q, K, V 矩阵的不同确实是不同大模型在“数学层面”表现出差异的直接原因(因为它们是训练出来的核心参数),但导致这些参数不同的,是它们背后的架构设计、训练数据和训练方法。
深入解读“参数”,“体积”,“上下文”概念
这三个概念构成了大模型部署中的**“不可能三角”**。在物理硬件资源(比如显存和算力)有限的情况下,你永远在它们三者之间做艰难的权衡。
我们用最直观的维度对它们进行一次深度解剖:
1. 参数 (Parameters) —— 模型的“智商”与“脑细胞”
-
本质: 模型内部那些经过海量数据训练出来的权重矩阵(如 及前馈网络)中具体数字的总和。
-
决定了什么: 逻辑推理能力、语言连贯性、指令遵循能力和知识储备。
-
深度解读:
-
涌现能力(Emergent Abilities): 大模型界有一个共识,当参数量跨过某个阈值(比如 300 亿或 700 亿)时,模型会突然“开窍”,展现出极强的复杂推理能力。
-
任务适配度: 如果只是做简单的文本翻译或语法纠错,几亿(比如 0.5B)或几十亿(7B)参数的模型就够了。但如果要处理极具深度的文化内容——比如精准理解中文小说的潜在人物动机、拆解复杂场景,或者体会中文歌词里的隐喻和情感基调——这就需要模型拥有极高的“情商”和“智商”,通常需要大参数模型(如 32B 或 70B 以上)才能输出高质量的剧本或提示词。
-
2. 体积 (Volume) —— 模型的“物理重量”与“存储占用”
-
本质: 这些“脑细胞(参数)”在计算机硬盘或显卡显存(VRAM)中实际占用的 GB 数。
-
决定了什么: 部署的硬件门槛。 它直接决定了这套系统是能在本地消费级显卡上跑,还是必须去租昂贵的云端服务器(VPS)。
-
深度解读:
-
核心公式:
模型体积 = 参数量 × 数据精度(字节) -
精度的魔法: 一个 14B(140亿参数)的模型,如果用标准的半精度(FP16)加载,体积大约是 28GB。如果你把它部署在一个拥有 16GB 显存的本地计算节点上,连加载都加载不进去,直接崩溃。这时候就必须使用量化(Quantization)技术。将它压缩到 INT4(4位整数,每个参数 0.5 字节)后,它的体积会骤降到 7GB 左右,这样就能轻松塞进显存了。
-
3. 上下文大小 (Context Window) —— 模型的“工作台面积”
-
本质: 模型一次性能够接收的输入(Prompt)加上它生成的输出(Response)的 Token 总数上限。
-
决定了什么: 单次处理超长文本的能力。
-
深度解读:
-
显存黑洞(KV Cache): 这是工程部署中最容易踩坑的地方。上下文不仅是个数字,它是实打实的物理显存占用。模型在阅读和生成时,需要把每个词的计算中间态(K 和 V 矩阵的结果)存在显卡里。
-
指数级膨胀: 随着输入文本的变长(比如一次性输入一整章几万字的小说,或者几首完整的长歌词),KV Cache 占用的显存会呈线性甚至指数级膨胀。
-
简单来说,上下文窗口(Context Window)是“目标上限”,而 KV Cache 是实现这个目标所需要付出的“物理代价(显存)”。
为了把这事说清楚,我们把它们拆解成三个部分,看看在实际运行中它们是如何相爱相杀的。
1. 为什么会有 KV Cache?(本质是“空间换时间”)
大语言模型生成文字是“自回归”的,也就是一个词一个词往外蹦。
假设你正在让模型根据一段极长的小说文本生成视频分镜脚本。当模型生成第 1001 个词时,它需要结合前 1000 个词的语境。如果没有 KV Cache,模型就得把前 1000 个词的 K(Key)和 V(Value)矩阵全部重新计算一遍。等生成第 1002 个词时,又得把前 1001 个词重新计算一遍……这会导致极度的算力浪费,生成速度会慢得像蜗牛。
所以,工程师发明了 KV Cache(键值缓存):把之前已经计算好的所有 Token 的 K 和 V 保存到显存里。下次生成新词时,直接从显存里读取历史记录,只计算当前这一个新词的注意力即可。
代码段
graph TD
subgraph Without_KV_Cache [Without KV Cache / 无缓存机制]
direction TB
W1[Past Tokens 1 to N-1 / 历史词汇] --> W2(Recalculate Q, K, V / 重新计算全量矩阵)
W2 --> W3[Generate Token N / 生成新词]
end
subgraph With_KV_Cache [With KV Cache / 有缓存机制]
direction TB
K1[Saved K, V / 显存中已保存的历史KV] --> K3(Calculate Q for Token N only / 仅计算当前词的Q)
K2[Token N / 当前输入词] --> K3
K3 --> K4[Generate Token N / 生成新词]
end2. 致命羁绊:上下文窗口越大,KV Cache 越吃显存
**上下文窗口(Context Window)**指的是模型一次性最多能处理多少个 Token(比如 8K, 32K, 128K)。
这里的关系非常直接:上下文窗口里的每一个 Token,都需要在 KV Cache 中占据一块实实在在的显存空间。
当你在本地管线中输入几万字的小说或长篇歌词时,即使你用的是拥有顶级算力和大显存的 RTX 5080,也会面临严峻的考验。因为显存的消耗分为两部分:
-
静态消耗: 固定的模型权重(Model Weights)。这部分加载完就不变了。
-
动态消耗: KV Cache。随着你输入的小说越来越长,或者生成的文本越来越多,KV Cache 会呈线性增长。如果上下文窗口开得太大,KV Cache 最终会撑爆剩下的所有显存,导致 OOM(Out of Memory)崩溃。
代码段
graph LR
subgraph VRAM_Allocation [GPU VRAM Allocation / 显卡显存分配]
direction LR
M[Model Weights / 模型权重<br>Fixed Size / 固定大小] --> GPU[(GPU VRAM / 显存池)]
C[Context Window / 上下文窗口<br>e.g., Novel Text / 小说长文本] --> K
K[KV Cache / 缓存区<br>Dynamic Size / 随文本长度动态增长] --> GPU
GPU -- "Exceeds Limit / 突破显存上限" --> Crash((OOM Crash / 显存溢出))
end3. 面对超长文本的拯救方案
既然 KV Cache 如此庞大,想要在有限的硬件上塞进更长的上下文窗口,业界通常会采用以下几种技术来给 KV Cache “瘦身”或提升管理效率:
-
量化缓存(KV Cache Quantization): 将原本高精度(如 FP16)的浮点数压缩成低精度(如 INT8 或 INT4),直接把 KV Cache 的体积砍掉一半甚至四分之三。
-
GQA / MQA(分组查询注意力): 这是架构层面的优化,现在的开源大模型(如 Llama 3, Qwen)都在用。它让多个注意力头“共享”同一组 K 和 V,从而成倍地减少需要存储的数据量。
-
PagedAttention(分页注意力): 这是 vLLM 等推理框架的核心技术。它像操作系统的虚拟内存一样,把连续的 KV Cache 打散成固定大小的“页面”动态分配,消除了显存碎片,极大地提升了长文本吞吐量。
代码段
graph TD
subgraph Optimization_Strategies [KV Cache Optimization / 缓存优化方案]
direction TB
O1[Long Context Input / 超长文本输入] --> O2{Solutions / 解决路径}
O2 --> O3[Quantization / 量化压缩 INT8或INT4]
O2 --> O4[PagedAttention / 分页内存碎片管理]
O2 --> O5[GQA / 共享注意力头结构]
O3 --> O6[Reduce VRAM Usage / 显著降低显存占用]
O4 --> O6
O5 --> O6
end总结一下:
上下文窗口是**“你想让 AI 读多长的小说”,而 KV Cache 是“AI 读小说时需要在脑子(显存)里做多少笔记”**。书越厚,笔记就越多,对硬件显存的压榨就越狠。
现实碰撞:硬件里的“零和博弈”
当你要搭建一个持续运行的网关(如 OpenClaw)或一条自动化的内容生成流水线时,这三个概念会在你的**显卡显存(VRAM)**里发生激烈的抢地盘大战。
假设你的硬件物理上限是 16GB 显存,总容量是固定的:
总显存 (16GB) = 模型体积占用 + 上下文 KV Cache 占用 + 系统冗余
这就逼着工程师必须做出选择:
-
策略 A(重智商,轻上下文): 选择一个极其聪明的量化版大模型(比如 14B INT4,占用 ~7GB)。剩下给上下文的显存就不多了。这意味着它生成的提示词质量极高,但你每次只能喂给它几百字的短语或一小段歌词,必须切碎了处理。
-
策略 B(重上下文,轻智商): 选择一个不太聪明的小模型(比如 3B FP16,占用 ~6GB)。留出了大量显存做 KV Cache,你可以一次性把整章小说扔给它。但由于模型“智商”不够,它可能在阅读中间时就迷失了重点,提取出毫无逻辑的废话。
总结:
-
参数是基础能力(大脑多强)。
-
体积是物理限制(头骨多大)。
-
上下文是短期吞吐量(桌子多宽)。
在实际开发生成式管线时,强行追求极大的“上下文大小”往往是不经济的,合理利用高“参数”模型的推理能力,配合外部工程手段才是王道。
所以并不是上下文越大越聪明吗?
“上下文窗口大”绝不等于“模型聪明”。 这两者在物理层面和算法层面上,对应的是完全不同的能力。
我们可以用一个**“工作台与打工人”**的比喻来拆解:
1. 聪明程度(智商) = 模型的“参数量”与“训练质量”
-
这是打工人的“专业能力和学历”。
-
就像我们之前聊过的,它是那几十、几百亿个 Q、K、V 矩阵中沉淀下来的“长期记忆”和“逻辑推理能力”。
-
一个 70B(700亿参数)的模型,往往在逻辑推理、复杂代码编写上,直接碾压 7B(70亿参数)的模型,无论它的上下文有多大。
2. 上下文窗口 = 模型的“短期记忆”与“工作台面积”
-
这是打工人的“办公桌有多大”。
-
上下文窗口决定了模型一次性能看多少份文件(输入),以及能写多长的报告(输出)。
把这两个概念组合起来,现实中会出现极其反直觉的现象:
-
桌子很大,但人不太聪明的“笨蛋”: 如果你把一个 7B 的小模型,通过数学技巧强行拉伸到 128K 的上下文。这就好比给一个小学生一张巨大的会议桌,上面堆满了 10 万字的资料。他确实能把这些资料都摊开在桌面上(没有报 OOM 显存溢出错误),但你让他总结核心观点时,他根本理解不了那么复杂的逻辑,最后只能给你胡言乱语。
-
桌子很小,但极其聪明的“天才”: 一个拥有极其强大逻辑能力的 70B 模型,哪怕它的上下文窗口只有 8K(工作台很小)。只要你把资料切成小块,一点点递给他看,他给出的洞察和分析会极其精准深刻。
3. 长上下文的致命弱点:“中间迷失”(Lost in the Middle)
这是大模型学术界目前非常头疼的一个普遍问题。
即使是那些号称支持 100 万上下文的最顶尖大模型,它们在阅读超长文本时,注意力也分布得极度不均匀:
-
它们对文本的开头和结尾记忆犹新(准确率极高)。
-
但如果你把关键信息藏在十万字长文的中间部分,它们大概率会直接忽略掉或“看漏了”。
结合实际应用场景来看:
想象一下,如果你想把一整章几十万字的中文小说,或者几百首长篇歌词直接塞给模型,让它一次性帮你提炼出里面所有的关键场景和人物情绪,用来生成分镜脚本。如果你过分迷信“大上下文窗口”,一股脑全塞进去,模型极有可能会把小说中间出场的人物关系完全搞混,或者漏掉歌词中段的重要意象。
相反,在这个时候,“聪明程度”比“工作台面积”重要得多。一个真正聪明的系统架构,不会依赖无限大的上下文,而是会让大模型配合合理的文本切块策略,逐段进行精准的高质量提取。
所以,评估一个模型,永远是推理能力(智商)优先,上下文窗口够用就行。
AI Agent
这几年 AI Agent 的变化很快。
最早大家还只是把 ChatGPT、DeepSeek 当高级问答工具,现在 Claude Code、Codex 这类工具已经能读项目、改代码、跑命令、做验证。对游戏开发来说,这就不只是“写代码更快一点”了,而是开发流程本身开始被重新拆开。
梦开始的地方:AI Chatbot
也就是 ChatGPT、DeepSeek 刚开始那种用法:纯聊天。
不过这时候已经可以问技术问题,也可以让它产出代码,只是需要我们自己手动复制粘贴到项目里。这也是为什么很多 LLM API 一开始都是 completion、chat/completion 这类接口,本质上还是“你问我答”。
大多数 AI CLI 的 Chat 模式也是这么来的:只输出文字,不直接改项目。
LLM的两大生态阵容
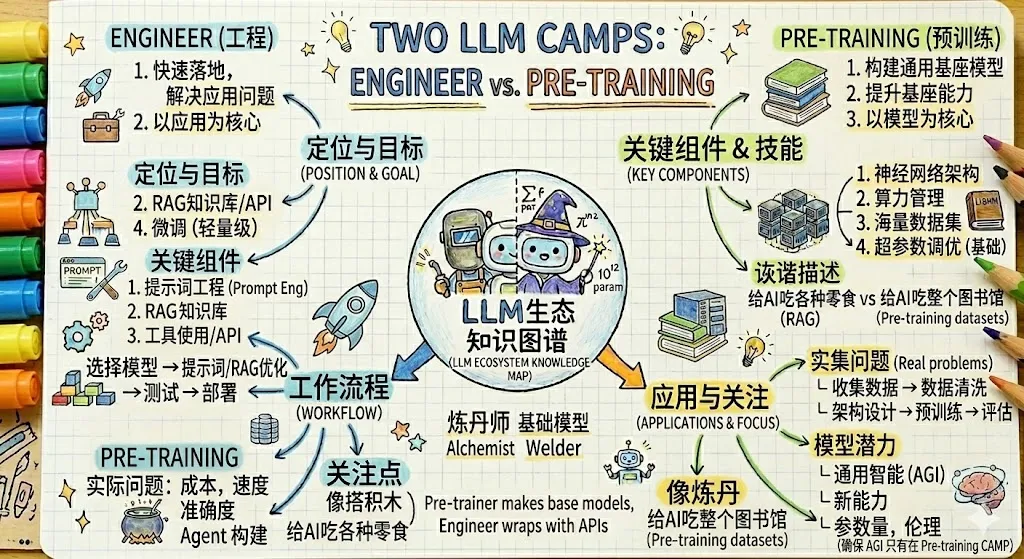
两大阵营并不是敌对关系,很多时候是互相合作、互相成全。
对我们日常 AI 应用来说,大多数工作其实集中在项目 rule.md、skill 开发、MCP 开发这些地方,已经足以应对 80% 以上的场景。
现在主流大模型很多,而且各自都有一骑绝尘的领域,一般也没有自己训练或微调的必要,当然更多时候是没那个条件。
- Gemini:超绝的长文本理解和推理能力,让他在小说创作,日常聊天,学术分析,论文分析上绝对领先
- Claude:仍然是世界综合能力最强代码生成模型
- GPT:如果Claude是锐意进取的新生代天才程序员,GPT就是老一辈的技术专家,你可以说他慢,但不能质疑它的代码能力,很多Claude犯错的地方他都能一遍过。此外,由于是ChatGPT出身,其日常聊天能力也非常棒,目前最适合作为OpenClaw的驱动模型
当然了,有没有需要微调开源模型的时候?也有。
比如我想让 AI 在某个固定世界观、背景设定下进行文学创作,微调数据的效果通常会比单纯堆提示词更稳。
什么是AI Agent
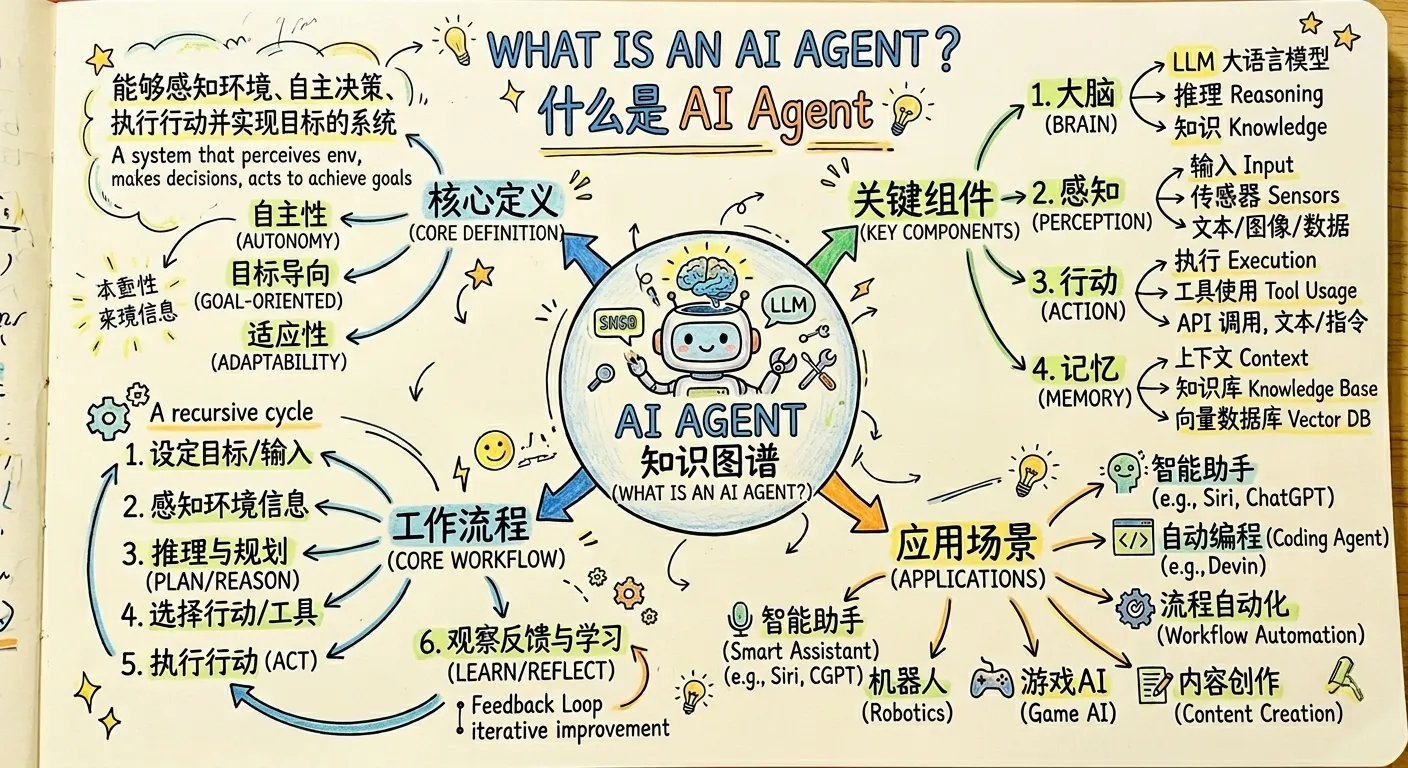
Agent 顾名思义,就是具有一定自主行为能力的智能助手。AI Agent 基于大模型,叠加记忆、工具调用、自主推理和规划能力,用来解决更复杂的问题。简单粗暴一点说:AI Agent = 大模型 + 记忆 + 工具 + 规划。
比如我们常用的 Claude Code、CodeBuddy、Codex 这些工具,都算 AI Agent。
Claude Code架构分析
Claude Code 目前是我觉得最值得拆解学习的 AI Agent 工具之一。
功能架构
其中 Skills 和 MCP 模块后面会重点讲,它俩是增强 AI 能力的关键。
flowchart TB
subgraph UserLayer["User Layer"]
Terminal["<b>Terminal / IDE</b><br/>- Input: natural language<br/>- Input: /slash commands<br/>- Output: streaming text"]
style Terminal fill:#d4e6f1,stroke:#2874a6
end
subgraph CoreEngine["Core Engine"]
SessionMgr["<b>Session Manager</b><br/>- Maintains conversation state<br/>- Handles tool_use loop<br/>- Manages stop conditions"]
style SessionMgr fill:#fadbd8,stroke:#c0392b
PromptBuilder["<b>Prompt Builder</b><br/>- System prompt construction<br/>- CLAUDE.md injection<br/>- Tool schema generation"]
style PromptBuilder fill:#fadbd8,stroke:#c0392b
end
subgraph PluginLayer["Plugin Layer"]
PluginLoader["<b>Plugin Loader</b><br/>- Scan ~/.claude/plugins/<br/>- Parse plugin.json manifest<br/>- Auto-discover components"]
style PluginLoader fill:#d5f5e3,stroke:#1e8449
CommandReg["<b>Command Registry</b><br/>- /commit, /hookify, etc.<br/>- Markdown + YAML frontmatter<br/>- $ARGUMENTS injection"]
style CommandReg fill:#d5f5e3,stroke:#1e8449
AgentReg["<b>Agent Registry</b><br/>- Subagent definitions<br/>- Model/color config<br/>- Tool restrictions"]
style AgentReg fill:#d5f5e3,stroke:#1e8449
SkillMatcher["<b>Skill Matcher</b><br/>- Context-based activation<br/>- SKILL.md parsing<br/>- Auto-inject to prompt"]
style SkillMatcher fill:#d5f5e3,stroke:#1e8449
end
subgraph HookLayer["Hook Layer"]
HookDispatcher["<b>Hook Dispatcher</b><br/>- Event routing<br/>- hooks.json parsing<br/>- Timeout handling (10s)"]
style HookDispatcher fill:#fdebd0,stroke:#d68910
RuleEngine["<b>Rule Engine</b><br/>- config_loader.py<br/>- rule_engine.py<br/>- Regex/contains matching"]
style RuleEngine fill:#fdebd0,stroke:#d68910
end
subgraph ToolLayer["Tool Layer"]
ToolExec["<b>Tool Executor</b><br/>- Permission checking<br/>- Sandboxed execution<br/>- Result formatting"]
style ToolExec fill:#e8daef,stroke:#7d3c98
Bash["Bash<br/>spawn()"]
Read["Read<br/>fs.read()"]
Write["Write/Edit<br/>fs.write()"]
Search["Grep/Glob"]
Git["Git ops"]
style Bash fill:#e8daef,stroke:#7d3c98
style Read fill:#e8daef,stroke:#7d3c98
style Write fill:#e8daef,stroke:#7d3c98
style Search fill:#e8daef,stroke:#7d3c98
style Git fill:#e8daef,stroke:#7d3c98
end
subgraph ExternalLayer["External Services"]
AnthropicAPI["<b>Anthropic API</b><br/>- POST /v1/messages<br/>- Tool calling protocol<br/>- SSE streaming"]
style AnthropicAPI fill:#fcf3cf,stroke:#b7950b
FileSystem["<b>File System</b><br/>- Project codebase<br/>- .claude/ config<br/>- hookify rules"]
style FileSystem fill:#f5f5f5,stroke:#616161
MCP["<b>MCP Servers</b><br/>- External tools<br/>- Custom integrations"]
style MCP fill:#f5f5f5,stroke:#616161
end
Terminal --> SessionMgr
SessionMgr --> PromptBuilder
PromptBuilder --> PluginLoader
PluginLoader --> CommandReg & AgentReg & SkillMatcher
PromptBuilder --> AnthropicAPI
AnthropicAPI -->|"tool_use"| HookDispatcher
HookDispatcher --> RuleEngine
RuleEngine <--> FileSystem
RuleEngine -->|"allow"| ToolExec
RuleEngine -.->|"block"| SessionMgr
ToolExec --> Bash & Read & Write & Search & Git
Bash & Read & Write & Search & Git <--> FileSystem
ToolExec -->|"tool_result"| SessionMgr
SessionMgr --> AnthropicAPI
AnthropicAPI -->|"text response"| Terminal
PluginLoader --> MCP消息流转
flowchart TB
subgraph ClientSide["🖥️ Client Side (本地)"]
direction TB
subgraph UserInterface["<b>User Interface Layer</b><br/>职责: 用户交互"]
CLI["<b>Terminal CLI</b><br/>- 接收用户输入<br/>- 渲染流式输出<br/>- 处理 /slash 命令"]
style CLI fill:#d4e6f1,stroke:#2874a6
end
subgraph BusinessLogic["<b>Business Logic Layer</b><br/>职责: 业务编排"]
Session["<b>Session Manager</b><br/>- 会话状态<br/>- Agentic Loop 控制<br/>- 错误重试"]
Prompt["<b>Prompt Builder</b><br/>- System Prompt 构建<br/>- Tool Schema 注入<br/>- 上下文窗口管理"]
style Session fill:#fadbd8,stroke:#c0392b
style Prompt fill:#fadbd8,stroke:#c0392b
end
subgraph ExtensionLayer["<b>Extension Layer</b><br/>职责: 可扩展性"]
Plugin["<b>Plugin System</b><br/>- 插件发现与加载<br/>- Command/Agent/Skill"]
Hook["<b>Hook Engine</b><br/>- 事件拦截<br/>- 规则匹配<br/>- 权限决策"]
style Plugin fill:#d5f5e3,stroke:#1e8449
style Hook fill:#fdebd0,stroke:#d68910
end
subgraph ExecutionLayer["<b>Execution Layer</b><br/>职责: 工具执行"]
ToolExec["<b>Tool Executor</b><br/>- Bash/Read/Write<br/>- 沙箱隔离<br/>- 结果格式化"]
FS["<b>File System</b><br/>- 代码读写<br/>- 配置文件"]
style ToolExec fill:#e8daef,stroke:#7d3c98
style FS fill:#f5f5f5,stroke:#616161
end
end
subgraph Network["🌐 Network Layer"]
HTTPS["<b>HTTPS/TLS 1.3</b><br/>- REST API 调用<br/>- SSE 流式响应<br/>- API Key 认证"]
style HTTPS fill:#fce4ec,stroke:#c2185b
end
subgraph AnthropicCloud["☁️ Anthropic Cloud (服务端)"]
direction TB
subgraph APIGateway["<b>API Gateway</b><br/>职责: 请求入口"]
Gateway["<b>Load Balancer</b><br/>- 流量分发<br/>- Rate Limiting<br/>- API Key 验证"]
style Gateway fill:#b3e5fc,stroke:#0277bd
end
subgraph InferenceService["<b>Inference Service</b><br/>职责: 推理调度"]
ReqParser["<b>Request Parser</b><br/>- 参数校验<br/>- Tool 定义解析<br/>- Message 格式化"]
Scheduler["<b>Request Scheduler</b><br/>- 队列管理<br/>- 优先级调度<br/>- GPU 资源分配"]
style ReqParser fill:#c8e6c9,stroke:#388e3c
style Scheduler fill:#c8e6c9,stroke:#388e3c
end
subgraph LLMEngine["<b>LLM Inference Engine</b><br/>职责: 模型推理"]
Tokenizer["<b>Tokenizer</b><br/>- Text → Token IDs<br/>- BPE/SentencePiece<br/>- Special tokens"]
ModelLoad["<b>Model Weights</b><br/>- Claude Sonnet/Opus<br/>- 参数量: 数百B<br/>- 分布式存储"]
Attention["<b>Transformer Forward</b><br/>- Multi-Head Attention<br/>- KV Cache<br/>- Flash Attention"]
Sampler["<b>Sampler</b><br/>- Temperature<br/>- Top-P / Top-K<br/>- Stop sequences"]
ToolParser["<b>Tool Use Parser</b><br/>- 检测 tool_use 输出<br/>- JSON Schema 验证<br/>- 结构化响应"]
style Tokenizer fill:#fff9c4,stroke:#f9a825
style ModelLoad fill:#fff9c4,stroke:#f9a825
style Attention fill:#fff9c4,stroke:#f9a825
style Sampler fill:#fff9c4,stroke:#f9a825
style ToolParser fill:#fff9c4,stroke:#f9a825
end
subgraph ResponseHandler["<b>Response Handler</b><br/>职责: 响应处理"]
Streamer["<b>SSE Streamer</b><br/>- Token 流式输出<br/>- 分块传输<br/>- 连接保持"]
Logger["<b>Usage Logger</b><br/>- Token 计数<br/>- 计费统计<br/>- 审计日志"]
style Streamer fill:#e1bee7,stroke:#7b1fa2
style Logger fill:#e1bee7,stroke:#7b1fa2
end
end
%% 连接关系
CLI --> Session
Session --> Prompt
Prompt --> Plugin
Plugin --> Hook
Session --> HTTPS
HTTPS --> Gateway
Gateway --> ReqParser
ReqParser --> Scheduler
Scheduler --> Tokenizer
Tokenizer --> ModelLoad
ModelLoad --> Attention
Attention --> Sampler
Sampler --> ToolParser
ToolParser --> Streamer
Streamer --> Logger
Logger --> HTTPS
HTTPS --> Session
Session -->|"tool_use"| Hook
Hook -->|"allow"| ToolExec
ToolExec <--> FS
ToolExec -->|"tool_result"| Session可以看到,整个CLI工具本质上就是一个RPC客户端,前端负责整理数据发给服务器,服务器用LLM开始作法,得到输出,返回指令数据给客户端,客户端做表现
RAG
A typical RAG application has two main components:
Indexing: a pipeline for ingesting data from a source and indexing it. This usually happens offline.
Retrieval and generation: the actual RAG chain, which takes the user query at run time and retrieves the relevant data from the index, then passes that to the model.
RAG即Retrieval Augmented Generation(检索增强生成),其主要分为两部分
- 索引 :从数据源提取数据并进行索引的管道。 这通常发生在线下。
- 检索和生成 :实际的 RAG 链,它在运行时接受用户查询并从索引中检索相关数据,然后将其传递给模型。
通俗点解释就是RAG会生成一份LLM能读懂的数据库,从而增强LLM的大脑知识量
Index
Index本身就是一个构建数据库的过程
- 加载 :首先是技能数据的加载,这里我们直接根据注释生成各个Action文档即可。
- 拆分 : 文本拆分器将大型
Documents拆分成较小的块。这对于索引数据和将其传递到模型都很有用,因为大块数据更难搜索,并且不适合模型有限的上下文窗口。由于技能Action的特殊性:因为我们把每个Action都设计成可复用的,所以其本身就是一个完整的语义单元,所以我们拆分的时候直接以技能脚本为单位拆分Chunk即可 - 存储 :我们需要一个地方来存储和索引我们的分割数据,以便日后进行搜索。这通常使用 VectorStore 和 Embeddings 模型来实现。
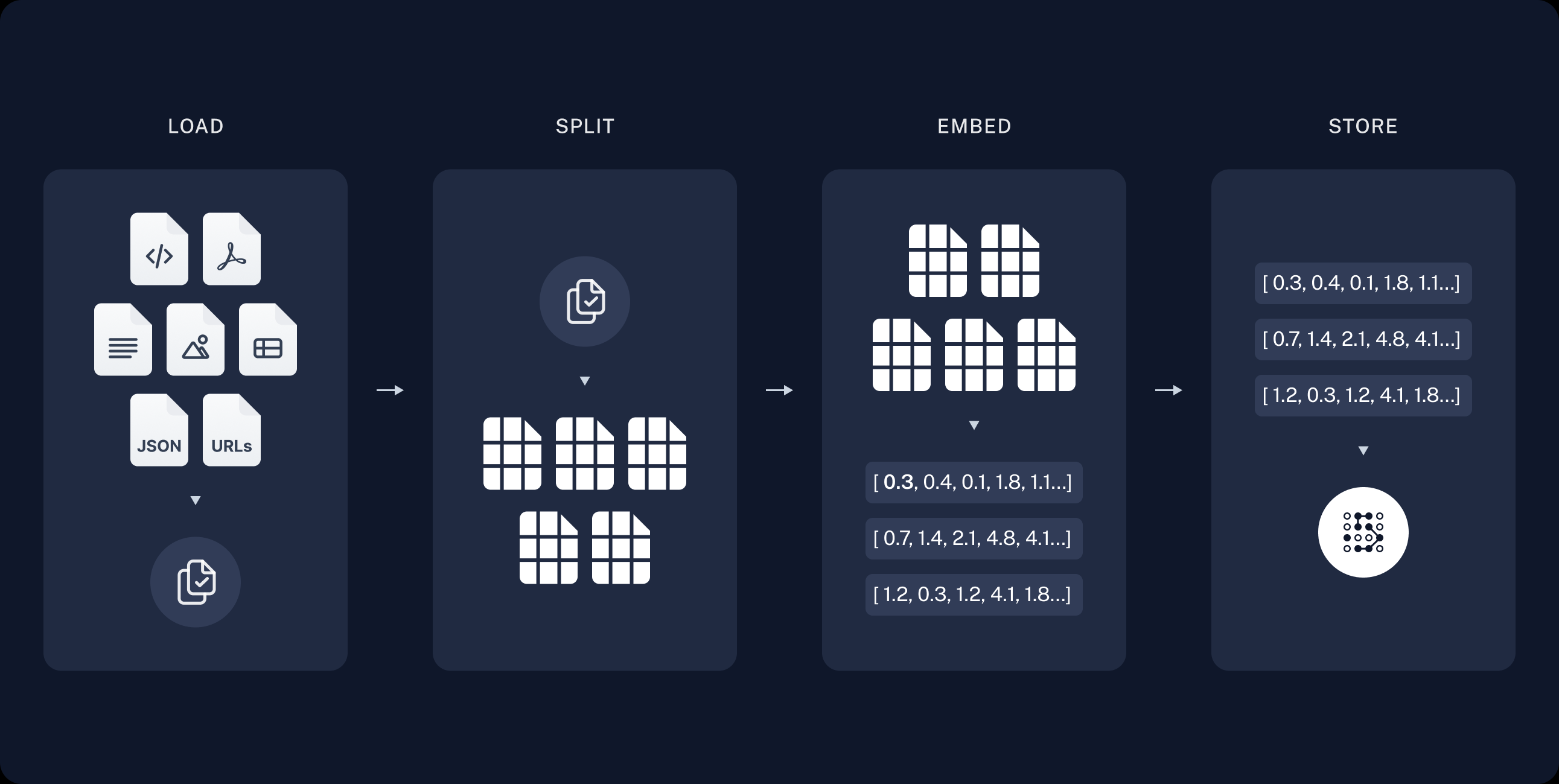
Retrieval and generation
检索和生成一般发生在应用运行的时候
检索 :给定用户输入,使用检索器从存储中检索相关分割。
生成 : ChatModel / LLM 使用包含问题和检索到的数据的提示生成答案
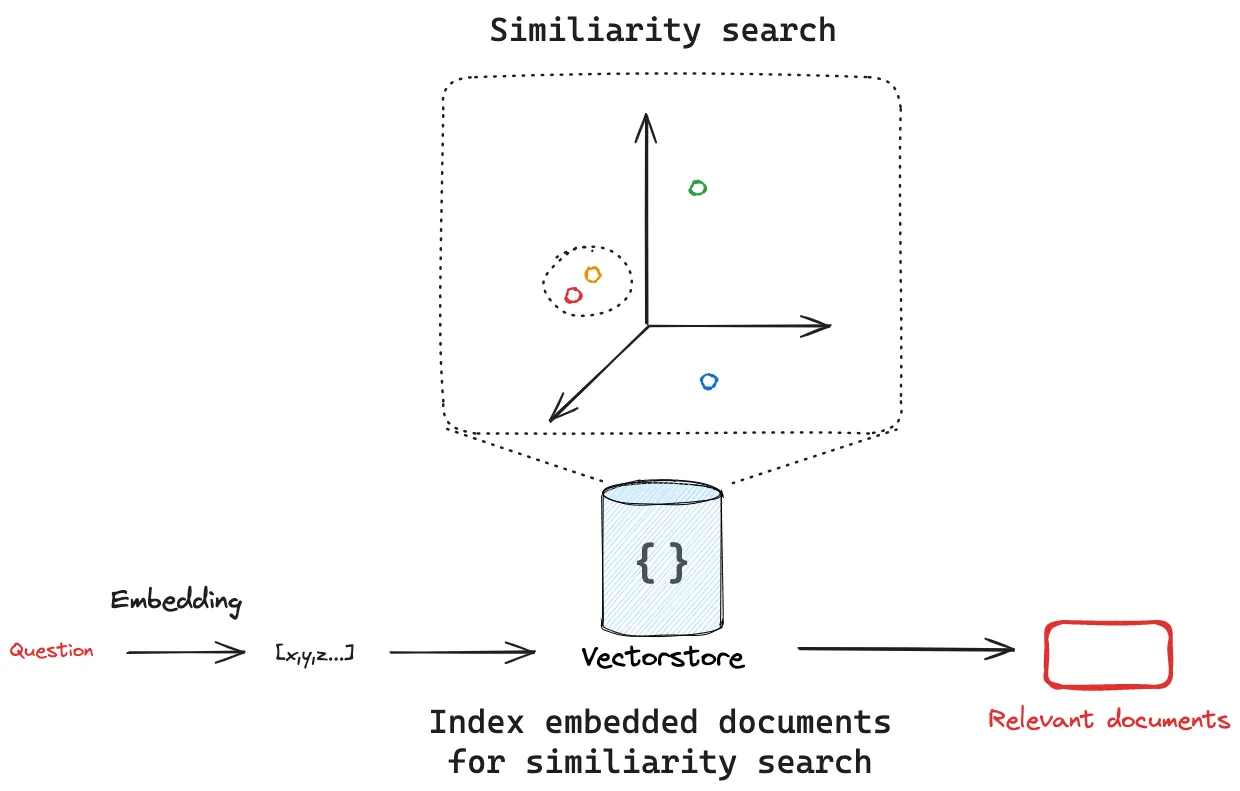
RAG与AI Agent协作示意
其实离我们最近的RAG例子就是各个AI终端提供的代码库索引功能,能让AI更准确,更人性化的搜索代码

总结
从应用层面来说,从零开始研究RAG是不现实的,所以要用现有的RAG构建方式,可以去 HugeFace 找免费的Embedding模型,然后直接存入数据库即可
之所以先把RAG拿出来讲,是因为在可以预见的未来里,自主构建RAG对于模型适应能力的提升和工作效率的优化至关重要,我认为RAG是所有复杂需求里的AI基建中的重中之重
有几个主要原因:
- 由于Transformer训练架构的原理限制和摩尔定律,参数量和上下文很快就会边际效应,即:LLM本身数据量是有限的,且上下文窗口是有限的(即使可以通过各种方法扩充上下文),所以需要人为补充需要的信息
- 注意力稀释(Lost in the Middle): 即使模型能吃下几百万字,由于 Transformer 的注意力机制,它往往对开头和结尾的信息印象深刻,但容易忽略中间的细节。RAG 通过检索只提取最相关的片段,有效提高了信息的“浓度”和“信噪比”。
- 算力成本与延迟: 每次请求都把海量的背景资料全量塞进 Prompt 里,会导致推理时的计算量呈指数级上升,不仅 Token 成本极高,首字响应时间(TTFT)也会让人无法忍受。RAG 是一种**“按需加载”**的策略,用最低的成本解决了知识调用的问题。
- 目前业界普遍面临一个“数据墙(Data Wall)”危机:人类互联网上高质量的文本数据(如书籍、高质量论文、优质代码)即将被大模型吃干榨净。当预训练数据达到瓶颈时,靠扩大参数来提升模型内部的“世界知识”收益会越来越低。因此,外挂知识库(RAG)成为补充增量知识、私有知识和实时知识的唯一解。
- 对于复杂的创造,审查需求,只有RAG数据库能应对高频,准确,快速的查找需求
- 大模型的本质是概率机器: 它通过预测下一个词来生成文本,擅长的是“逻辑推理”和“语言组织”,而不是“死记硬背”。
- 确定性与可溯源: 审查和严谨的创作要求 100% 的准确(Factuality)。RAG 的架构本质上是把系统的**“记忆/存储”(交由向量数据库或关系型数据库)和“大脑/计算”(交由 LLM)分离开了。数据库负责提供绝对准确的事实依据,LLM 负责基于这些事实进行分析和总结。
RAG 的必然性,在于它用工程化的手段,弥补了 Transformer 在算力成本、长文本注意力以及生成确定性上的原生缺陷。
MCP
如果说 RAG 是给大模型配备了专属的“外挂图书馆”,那么 MCP(Model Context Protocol,模型上下文协议)就是给 AI Agent 安装了“标准化的万能 USB 接口”。

简单来说,MCP 解决的是 AI Agent “如何与现实世界(工具、数据、系统)安全且高效地连接” 的问题。对于构建具备自主能力的 Agent 来说,MCP 的重要性主要体现在以下三个维度:
1. 终结“烟囱式”开发,实现标准化接入
在 MCP 出现之前,如果你想让 AI Agent 读取本地文件系统、查询数据库或者调用外部 API,你需要为每一个数据源编写特定的对接代码和 API 封装。
- MCP 的改变: 它提供了一套类似于 USB-C 的统一标准(Client-Server 架构)。开发者只需要写一个 MCP Server,任何支持 MCP 的 AI 客户端(如 Claude Desktop 甚至你自研的 Agent 框架)都可以无缝接入这些能力,极大地降低了工具集成的开发成本。
2. 从“被动检索”到“主动读写”的跨越
RAG 主要是解决“读”和“找”的问题,但一个真正的 AI Agent 需要具备行动力(Action)。
- 结合 MCP,Agent 不仅能读取信息,还能安全地执行操作。比如,在开发你的视频生成软件时,你可以构建一个本地的 MCP Server,让 Agent 不仅能读取你的提示词和剧本文档,还能直接调用本地的渲染脚本,甚至在 Unity 环境中触发特定的场景构建指令。它让 Agent 拥有了“手和脚”。
3. 本地化部署的极致安全与解耦
对于追求数据隐私和本地算力最大化的开发者来说,MCP 提供了一层绝佳的隔离。
- 安全可控: 你的核心代码库、未发布的小说剧本或私有 API 不需要一股脑喂给大模型。大模型只是作为一个“推理大脑(Client)”存在,它通过 MCP 向你部署在本地的“数据服务器(Server)”发出请求。你可以精确控制 MCP Server 能暴露哪些权限给大模型,实现了逻辑计算与数据存储的完美解耦。
一句话总结: RAG 决定了 Agent “懂多少”,而 MCP 标准决定了 Agent “能做多复杂的事” 以及**“扩展的上限有多高”**。
示例
引用自: https://devblogs.microsoft.com/dotnet/build-a-model-context-protocol-mcp-server-in-csharp/
说了这么多,可能还是有点抽象,来用C#的MCP SDK举个例子:
1 | using System; |
这段代码提供了两个能力:
- 获取用户账户余额列表
- 根据名字获取指定用户账户余额信息
这是原本AI Agent绝对不具备的能力,相当于直接拓展了AI Agent的能力,类比到游戏项目中各个模块也是一样,可以利用MCP把游戏项目中各个模块原本对AI来说不可见,不可读的(或者说不易读的)资源转化成AI能理解的数据,从而让AI更好的理解和协助开发项目
Skills

如果大模型(LLM)是 Agent 的“大脑”(负责思考和规划),RAG 是它的“记忆库”(负责查阅资料),MCP 是它的“万能数据接口”(负责连接外部环境),那么 Skills(技能/工具包)就是 Agent 的“手和脚”,或者是安装在它身上的**“应用程序(App)”**。
简单来说,Skills 决定了 Agent 最终能对现实世界产生什么“物理/实质性”的影响。
我们可以从以下三个维度来概括它们的关系:
1. 跨越“只会说”到“真正做”的鸿沟
LLM 本质上只是一个文本生成器,它只会输出字符串。如果没有 Skills,Agent 永远只是个“聊天机器人”。
-
当赋予了
Execute_Python_Code这个 Skill 后,它就成了程序员。 -
当赋予了
Search_Web这个 Skill 后,它就成了研究员。 -
Skills 是 Agent 行动力的基本单元。 它将 LLM 生成的“文本意图”转化为可以被计算机执行的“具体指令”。
2. 动态编排与自主调用(ReAct 机制)
Agent 最强大的地方在于,它不需要你硬编码每一步的流程。 面对一个复杂需求,Agent 的大脑会进行“推理(Reasoning)”,然后从它的**技能库(Skill Pool)**中自主选择并组合合适的 Skills 去“行动(Acting)”。如果一个 Skill 执行失败,它还会根据报错信息换一个 Skill 再试。
3. 实战场景下的具象化体现
例如我们需要AI自动拉取自己的BUG单,分析BUG单内容,搜查代码,最终解决BUG,提交GIT
就可以开发一个Skill,指示AI将如何执行这个流程:
- 使用xxx MCP拉取用户Id为xxx的前10个BUG
- 分析BUG单中的描述,视频,图片,报错堆栈,日志
- 查询代码库
- 利用xxx MCP分析xxx资源是否合规,是否为BUG来源
- 提供修复建议或直接修复
- 提交GIT
- 总结此次BUG修复的流程和结论
在这个工作流中,Agent 就像一个主导全局的导演,而每一个 Skill 就是具体的摄影师、灯光师,演员,道具组和剪辑师。
梦将去往何方:开发Agent
说实话,2026 年的今天,LLM 单看阅读、分析、代码生成能力,已经强到让我经常怀疑自己还会不会写代码。
但它依然不是万能按钮。尤其是在商业项目里,很多问题修复不只是改一行代码:可能要动资源、改配置、跑工具、看日志、做验证,还要照顾项目里各种历史包袱。Skill 当然有用,但 Skill 终究只是 Agent 的一层扩展,它还是会被 LLM 的幻觉、注意力涣散和上下文污染拖下水。
最痛苦的情况是:你把每个模块都做成了 AI 可读、可调用、可修改,也写了 Skill 去协调流程,但只要模型漏掉一个关键环节,尤其是漏掉验证,结果就会非常难看。第二天发现自己工位被实习生坐了,也不是完全没有可能。
超大规模代码重构也是类似。目前依然需要人先把重构步骤、验证路线、历史潜规则写清楚。只要漏掉一个犄角旮旯里的暗坑,BUG 查到明年都不奇怪。
所以问题不是 AI 不强,而是 LLM 的底层机制天然偏发散。它在聊天和创作时很舒服,但让它执行严肃工程任务时,就必须加上流程约束。
原生 Agent,比如单纯依赖一段长 Prompt 的 ReAct 模式,很像一个没有项目经理盯着、随性发挥的天才。LangGraph、Dify 这类框架之所以能减少失控,本质上就是把“现代软件工程的确定性”塞回流程里。
具体来说,它们主要靠下面几件事勒住大模型:
1. 从“自由发散”到“图结构约束” (Graph & Workflow)
原生 Agent 的执行路径大多是动态猜出来的,步骤一复杂,就很容易迷路或者陷入死循环。
-
LangGraph 的思路: 把 Agent 的思考和行动过程定义成一张有向图(Graph)。节点和边都写清楚,比如“生成提示词”之后必须进入“语法校验”,不能想去哪就去哪。
-
Dify 的思路: 提供可视化 Workflow。通过节点编排,把复杂任务拆成小任务。模型不再负责整个长链路,而是在特定节点里做特定事情,单次推理复杂度自然会低很多。
2. 精确的“状态管理” (State Management) 与上下文隔离
导致大模型幻觉的一个关键原因是上下文污染。把所有历史对话、报错信息、中间草稿全塞进一个 Prompt 里,模型很快就会精神分裂。
-
全局与局部状态: LangGraph 这类框架会引入严格的 State 概念。每流转到一个新节点,只把这个节点真正需要的上下文喂给模型,而不是把整锅汤都倒进去。
-
变量强校验: 上一个节点的输出如果格式不对,比如要求 JSON,模型却输出 Markdown,框架就应该在节点之间校验和重试,而不是让脏数据继续往下游传。
3. “人类在环” (Human-in-the-Loop) 的硬控
完全自主的 Agent 在现阶段并不现实。关键决策上,人类还是要能踩刹车。
-
这些框架允许在 Graph 或 Workflow 的关键节点设置断点(Breakpoints)。
-
在复杂内容生成流水线里,比如把几十万字小说拆成分镜,大模型很容易出现角色设定崩塌或时间线错乱。比较稳的做法是:Agent 生成分镜后先停住,人类确认没问题,再让它调用本地算力执行高成本渲染。该停的时候停,别装全自动。
4. 颗粒度极高的可观测性 (Tracing & Debugging)
原生 Agent 出问题时,最恶心的是你只知道结果错了,却不知道它到底在哪一步开始跑偏。
-
无论是 LangGraph 配合 LangSmith,还是 Dify 内置日志,都在补 Tracing 能力。
-
你要能看到第 3 个节点第 2 次循环里,Agent 到底是检索到了哪条错误 RAG 数据,还是工具参数传错了。能被观测,才有机会被修正。
总结来说: AI 充满概率和不确定性,而传统软件工程追求严谨和确定性。LangGraph、Dify 这类框架做的事情,就是在两者之间架桥,用流程和规则把大模型关进“逻辑的笼子”里。
术业有专攻。我们完全可以基于这些框架,为那些必须严肃控制的领域开发专门 Agent。既吃到 AI 的便利,又别把安全性和正确性全押给模型临场发挥。
游戏行业野望
说了这么多基础概念,最后还是要回到游戏。
AI 对游戏行业到底意味着什么?我现在的判断比较直接:在渲染、美术、管线这些领域,它短期更像提效工具;真正可能改变游戏形态的地方,是 GamePlay 和 UGC。
AI 时代的游戏研发:从提效工具到玩法生产力
一、核心论点:AI 的价值会分层
在现代游戏研发管线里,AI 的价值不是一刀切的。
对纯 Rendering(渲染)来说,除了硬件驱动的神经渲染(Neural Rendering / DLSS)和基于神经网络的 GI Trick,AI 更多时候还是在做工程基建提效:辅助 Shader 编写、渲染管线优化、RenderDoc / Pix 截帧日志分析。它能省时间,也能帮我们少熬几晚,但并不一定直接改变画面的底层逻辑。
但在 GamePlay(核心玩法) 里,情况就不太一样了。GamePlay 本质上是逻辑、规则、交互和叙事的组合。AI 一旦介入,就有机会打破状态机(FSM)和行为树(Behavior Tree)那种“策划和程序提前穷举一切”的模式,让游戏从“预设脚本呈现”慢慢走向“动态沙盒涌现”。更狠的是,它会把 UGC 的门槛从代码、触发器、蓝图连线,继续往自然语言方向压。
二、PGC 视角:GamePlay 从死板走向涌现
在专业开发侧,AI 让我比较期待的不是“帮忙写两段配置”,而是它可能让深度动态系统真正落地。
-
具象化智能体(Agentic NPCs): 传统 NPC 很多时候还是
if-else条件树,玩家多问两句就露馅。结合 RAG 和长文本记忆之后,NPC 可以拥有自己的记忆、性格和目标,在复杂社会生态里自主交互,产生一些没有被策划硬编码过的剧情。 -
多模态表现层的实时适配: 动态生成的 GamePlay 不能只停留在文本层。它最好还能影响音频、表情、动作和镜头。比如通过情感标签驱动 Wwise 的混音状态,再配合 Audio2Face 这类技术绑定面部骨骼(Blendshapes),让表现层跟逻辑层咬在一起。
-
自动化测试与动态难度调节(DDA): 强化学习(RL)和 AI 智能体可以 24 小时做拟真 Playtesting。它们不仅能帮我们扫 NavMesh 漏洞、技能组合 BUG,也能通过大量模拟对战分析玩家习惯,做更细的难度平滑,尽量把玩家留在“有压力但不坐牢”的心流区间。
三、UGC 视角:门槛会被继续打下去
如果说 AI 对 PGC 是抬高上限,那么对 UGC 就是继续打门槛。
玩家不应该为了表达一个玩法想法,先去学触发器、Lua 脚本或者蓝图连线。会这些当然很好,但不会这些,不应该永远被挡在创作门外。
-
意图驱动的关卡生成(Intent-Driven Level Generation): 玩家通过自然语言 Prompt 或简单 2D 草图,驱动 AI 生成 3D 地形、摆放 Prefab,甚至自动烘焙光照和 NavMesh。建造从“手工拼乐高”变成“先说清楚你想要什么”。
-
Text-to-Skill(自然语言转技能逻辑): 这是我最关心的方向。玩家输入“半血以下召唤巨剑击飞敌人”这类描述,引擎内置 AI Agent 把它解析成标准化 C# 逻辑脚本或 ECS 组件数据。自然语言不一定是最终脚本,但它可以成为玩法表达的入口。
-
智能配表与系统级平衡(Automated Balancing): UGC 最容易崩的地方就是数值。AI Agent 可以接管 Excel / JSON 配置,在玩家设定机制原型后,通过后台高并发沙盒试跑,尝试抹平伤害曲线、CD 和资源消耗,给出兼顾爽感和平衡性的配置建议。
总结
当本地算力和模型能力继续往前走,未来的游戏本体很可能会越来越像一个轻量级开发平台。
我不想把它写成“玩家即创世神”这种大口号,但方向确实在那里:AI 不只是优化 GamePlay 的工具,它可能会逐渐成为 GamePlay 的一部分。游戏不再只靠开发团队预先塞内容,而是能围绕玩家意图持续生长。讲道理,这对 UGC 来说很诱人。
实践愿景
- 程序
- 代码自动审查
- 自动化BUG修复,需打通测试平台,BUG单平台,代码库,项目MCP基建的链路
- 测试提单AI规范化,包含更多AI可以识别的内容(文本,图片),BUG内容更详细
- BUG单平台提供API能力,可以通过curl直接拉取BUG单所有信息
- 代码库的云端可读性
- 项目各个模块开发自己的MCP工具,尽可能做到AI对模块全知全能,可随意获取(萃取资产信息,只返回AI需要的json内容),修改任何资产(prefab,assets,bytes)
- 此外BUG单中的日志信息尤为重要,这是唯一一个能让AI低成本感知到BUG发生时到底是什么环境,哪个步骤导致的问题,从而协助定位到具体代码逻辑,这就要求各模块需要开发一套跑测时专门给AI打印的日志系统,要求事无巨细
- 利用第一点的代码自动审查,确保正确性
- 自动化需求处理,需打通策划,美术工种的提单规范,提单平台,代码库,项目MCP基建的链路
- 因为游戏行业的特殊性,需求往往与资产息息相关,所以同样要求上面提到的项目MCP基建
- 利用第一点的代码自动审查,确保正确性
- 一般来说要求完全自动化的程序工作,需要开发自定义AI Agent,24小时运行在云端服务器,确保每个环节的安全性,正确性,仍然推荐各模块负责人最后审查一下代码
- 策划
- 技能配置,关卡配置自动生成,修改,审查工具
- 这部分的开发工作尤为复杂,因为涉及到游戏核心逻辑配置的拆解,修改,RAG数据库建立,审查,验证,修复,项目联调,实时预览工作。因为环节多,且逻辑性,精密性要求极高,需要开发非常复杂的AI Agent来满足需求
- 最终建议以网页形式呈现给策划,便于使用和预览
- 技能配置,关卡配置自动生成,修改,审查工具
可以看到,上面这些自动化需求,不是简单 Skill 就能全覆盖、全验证的。Skill 更适合处理非常具体的任务,比如战斗模块脚本开发,可以写一份 Skill 告诉 AI Agent 战斗脚本系统的代码结构和开发规范。
那有朋友可能会问:能不能通过 Skill 嵌套 Skill,把这些自动化工作全做了?
讲道理,目前我不太看好。因为这又回到了前面说的 AI 自由发散和幻觉问题。链路越长,某一步漏验证、漏上下文、漏资源约束的概率就越高。所以对于真正复杂的游戏生产流程,最后大概率还是要开发专门的 AI Agent,用工程系统把流程、验证和边界管起来。
实践示例
目前我看到比较成熟的实践例子,是米哈游的 AI 技能编辑:https://mp.weixin.qq.com/s/ONKM34FhdrJOoCFFuoeZEA
听朋友说米桑的 AI 应用已经到 Next Level 的程度了,连关卡都能一句话生成、修改。这个方向对 UGC 确实是重大利好。
我自己本身也对 UGC 很感兴趣,所以业余时间在维护一个 AI 配置生成工具:游戏技能配置AI Agent开发记录 。目标是开发一个能移植进任意项目的工具,让 AI 辅助甚至部分接管技能、关卡逻辑配置的生成、检查、建议和修复工作。
它的意义大概有两个:
- 解放策划生产力,降低试错成本。很多 BUG 修复和配置问题,可以先问 AI,而不是所有事情都等程序排期。新人也能在 AI 协助下更快上手项目配置。
- 继续把创作能力下沉到玩家侧。真到那一天,资源和技术不再是限制游戏创意的主要枷锁,拼的就是每个人的小巧思。这个画面,我还是挺期待的。
参考
3Blue的视频讲解,通俗易懂
《The Illustrated Transformer》
https://devblogs.microsoft.com/dotnet/build-a-model-context-protocol-mcp-server-in-csharp/
 微信
微信 支付宝
支付宝