
(译)上下文转向行为驱动的AI移动策略(Context Steering)
本文是对GameAIPro2_Chapter18_Context_Steering_Behavior-Driven_Steering_at_the_Macro_Scale 进行的中文翻译
译文
介绍
在游戏行业中,转向行为(Steering Behaviour)是非常普遍的。他们之所以这么流行,是因为其只需要使用简单组件就可以快速实现核心功能。
然而,转向行为并不适合用于某些类型的游戏。当玩家能够挑选并监控单个实体时,避免碰撞和自然的移动就变得非常重要。为了实现这一目标可能会导致行为组件的膨胀并变得紧耦合,实体运动逻辑也会变得脆弱和难以维护。
在本章中,我们将概述如何识别那些转向行为不太适合的游戏,并提出一种针对这些问题的新方法,它被称之为上下文转向行为(Context Steering)。上下文转向行为(Context Steering Monobehaviours)是小巧的和无状态的(StateLess),并提供任何行为本身所期望的运动约束。当上下文转向行为用于取代游戏F1 2011上的原转向行为时,代码库减少了4000行,但AI在避免碰撞、超车和执行其他有趣的行为方面表现得更好。
转向行为将会在何时表现得糟糕
转向行为系统用于在世界中移动一个实体。该系统由多个子行为组成。在每次Tick过程中,每个子行为被要求产出一个向量,表示它们希望实体如何移动。这些向量组合产生最终向量,呐,这就是Context Steering;这个系统原理如此简单也是它的优势之一。
请注意,行为产出的向量可以是期望的最终速度,也可以是对当前速度的修正力。本文章将会把行为输出的向量可视化为最终速度,它不会改变任何数据,但它会使图表更容易排列和理解。
想象一个在二维平面上可以自由移动的实体。该实体只想避开障碍和追逐目标。在图18.1所示的时间瞬间,场景中有两个可能的目标和一个障碍。
这里的理想结果是什么?假设我们在选择目标时唯一关心的是距离权重,实体应该向目标a移动,但是在路上存在障碍,所以向目标B移动是最好的。这个最终决定(向目标B移动)能由一些简单的行为衡量计算之后得出吗?
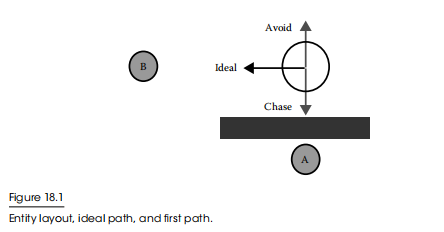
我们从两种简单的转向行为开始:追逐以接近目标,以及躲避障碍物。我们的躲避行为是看到了附近的障碍,并返回一个向量来避开它。追逐行为对障碍物一无所知,因此将返回到最近的目标(A)的一个向量。
行为系统结合了这些行为。让我们假设它们值是相同的。最终的向量非常接近于0,并且实体几乎不移动。玩家不会认为这是一个智能的实体!
多年来,转向行为系统已经发展出了一些补丁来应对这种情况。这里有一些可以解决这个僵局的方法:
- 我们可以为行为添加
权重,所以当附近有障碍时,躲避行为的权重会超过追逐行为。现在这个实体有一个强大的向北(上北下南)的速度,但在某个时刻,它将再次达到平衡。我们只是以一个新的权重参数为代价,成功地解决了这个问题。但是,当我们改变任何受这个权重影响的行为时,该权重参数值总是需要进行调整。 - 我们可以为行为添加
优先级,躲避是唯一一种在接近障碍时运行的行为,但在障碍附近的运动是非常单一的,并且不是很有表现力。最后,我们可以在追逐行为中添加一些对障碍的意识。它可以拒绝没有明确的目标路径或路径查找的目标,选择路径最短的目标。这两种方法都引入了追逐中的障碍的概念,从而增加了耦合。在大多数游戏引擎中,射线检测和路径查找要么是昂贵的,要么是异步的,这两者都引入了不同类型的复杂性。这使得追逐既不是“小巧的”,也不是“无状态的”。似乎没有一个好办法来解决这个问题。
这听起来像是一个刻意制造的例子,但它是基于一个真实的经验。在F1 2010中,躲避行为必须是非常强鲁棒的,这意味着它经常要求频繁和孤立地运行,主导AI赛车的移动方式。为了在AI中加入一些表达力,我们一遍又一次地扩展躲避行为,将其与多个其他行为相结合,并使其成为整体。到最后,它已经成一个老式的if/else块序列,只是包了层的转向行为的皮而已,这是一个维护噩梦。
AI对象成群结队时(Flocks versus Groups)
如果转向行为会如此糟糕,为什么它们如此受欢迎?因为不是所有的游戏都满足了上述条件来使问题明显。转向行为是一种统计学上的转向方法。大多数时候,他们会给你大致正确的方向。他们多久给你一次不一致或糟糕的结果,以及这对玩家有多糟糕,这些东西每个游戏对其重视程度或需求不一样。
转向行为最著名的应用是成群聚集,这并非巧合。在群集过程中,玩家通常是把这些实体当成一个行动组进行移动。这个行动组似乎有逼真的属性和不可预测但可信的(指不会互相残杀,哈哈)行为。鸟群的大小可以隐藏个体之间奇怪的不一致的运动或碰撞。在赛车类型中,玩家通常是在“行动组”中。此时,不一致的动作可能是显眼的和沉浸式的打破(军训的时候教官经常说,不要以为自己动作不到位我看不到,别人整齐划一,就你出岔子,我看的一清二楚)。它们可能导致错过超车机会,严重的超车堵塞,或在最坏的情况下与其他汽车发生碰撞。所以一般的转向行为并不太适合F1。
AI对象缺少对世界的感知时(Lack of Context)
我们现在了解了转向行为失败是什么样子的,以及什么类型的游戏都很重要。但我们还不知道为什么转向行为系统会有这个缺陷。一旦我们理解了这一点,我们就可以设计出一个解决方案。
一个单一的转向行为组件被要求返回一个表示其决策的向量,考虑到世界的当前状态。然后,该框架将尝试合并多个决策。然而,只是没有足够的信息来使合并这些决策成为可能。增加优先级或权重试图通过在行为结果中添加更多信息来使合并更容易,但这会转化为更大的麻烦。通过让追逐意识到障碍,我们可以使它产生更明智的结果,但这只是特殊的黑魔法合并步骤,并不是一个可扩展的解决方案。
有时候,导致一个行为无论如何都不想被执行的原因是:做出决定的背景和决定本身一样重要。这是避免碰撞行为的一个特殊问题,因为行为之间只能用期望速度这一语言进行交流,而不是不期望的速度。
聚焦于为什么,而不是怎么做(Toward Why, Not How)
直接返回一个决定,但有一些额外数据用于和其他行为做通信结合做决定,这不好。相反,如果我们可以询问一个行为是什么原因导致它将做出的决策,但跳过实际的决策步骤呢?如果我们能以某种方式合并所有这些上下文,一些与外部行为无关的处理器就会产生一个考虑到一切环境因素的最终的决定。
躲避的原因可能是,“我强烈地觉得我们不应该南”。追逐的原因可能是,“西有点有趣,南也很有趣”。这是一个整体的观点,而不是一个最后的决定。然后,这个框架挥舞着一根魔杖,结合了这些原因,揭示了最好的的决定是去西部。
最终的结果是,就好像追逐者意识到了障碍,并忽视了它感兴趣的目标,因为它被阻止了,而每个行为依旧只关注他们的所需要关注的。该系统是灵活多变的并且具有一致的躲避碰撞行为和小的无状态行为。
上下文映射(Context Maps)
上下文转向框架会处理上下文映射的内容。想象一下实体所关心的一切,投射到实体周围的圆周上,如图18.2所示。它就像一个一维图像,事实上,我们将在后面的章节中向你展示许多技巧。
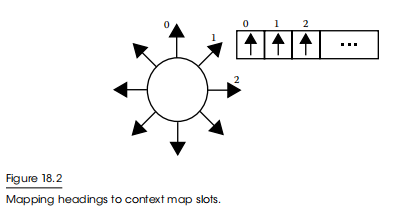
实际上,上下文映射是一个标量值数组,数组的每个槽位表示一个选择,槽位的内容表示行为对这个标题的强度。数组有多少个插槽是上下文映射的“分辨率”。通过使用这种数组格式,我们可以很容易地关联和合并不同的上下文映射。这就我们在不同行为之间进行仲裁的数据结构。
在每一帧中,该框架将会对每个行为访问两种不同的上下文映射:危险映射和兴趣映射。危险映射是对行为想要远离的目标内容。兴趣列表是行为想要走向的目标内容。
通过例子理解上下文映射(Context Maps by Example)
还记得我们之前的实体示例吗,让我们重写为使用上下文映射。我们可以通过考虑告知旧行为的决定的信息,并将这些信息存储在正确的上下文映射中来进行重写
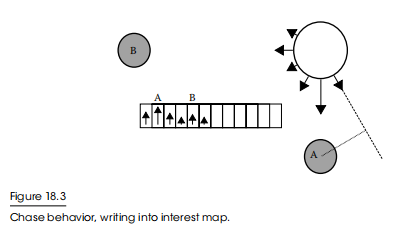
追逐行为(Chase Behavior)
追逐行为希望实体向目标移动,更喜欢靠近目标。然而,选择最佳目标需要做出决定,而我们并不想这样做。所以我们要把所有的目标写入兴趣列表中,用更低的强度表示更远的目标。
我们可以直接将一个向量指向一个目标,将其转换为一个地图槽,然后只写入该槽。这样一来,就可以捕捉到想要靠近期望目标而需要的移动方向。然而,我们也可以以目标(A)为中心,以往实体圆周发出的射线做垂线,垂线段越长,强度衰减越厉害(即向量点乘,重合程度越大,值越大,权重越大)。这捕捉了传递目标但错过它也是一件有趣的事情,即使这不是最好的行为。这种衰减的工作方式有很多力量和细微差别,让你对实体如何移动有很大的控制权。所有这些都可以通过对所有目标进行快速处理,使用一些调优常数和无状态函数来完成。所生成的兴趣列表如图18.3所示。
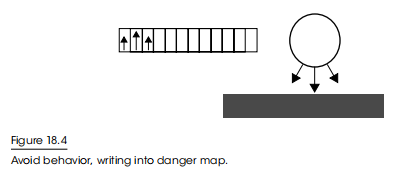
躲避行为(Avoid Behavior)
躲避行为希望实体至少与障碍物保持一个最小距离。我们将所有的障碍写入危险映射。危险映射中障碍物的强度表示到障碍物的距离。如果实体与障碍物超过了最小距离,则可以忽略它。同样,在障碍物周围的槽位值规律衰减也是一种有趣的做法,它会产生贴墙移动的效果。在这里实体需要绕过它而不是进入它自身以及其周围的隔离区。这种行为也是无状态且很小巧的。躲避行为如图18.4所示。
组合数据并进行解析(Combining and Parsing)
通过在多个映射上比较每个槽并取最大值,每个行为的输出可以与其他行为相结合。我们可以相加或平均这些插槽值,但我们不会再因为它后面有另一个障碍而避免一个特定的障碍,因为我们已经避开第一个障碍,而这就掩盖了来自第二个障碍的任何危险。通过组合,我们可以将所有的输出减少为一个单一的兴趣和危险映射。
下一步处理映射,将整个共享上下文萃取为一个单一的最终速度。这是如何发生的是游戏特定的;赛车游戏示例将有自己的实现。
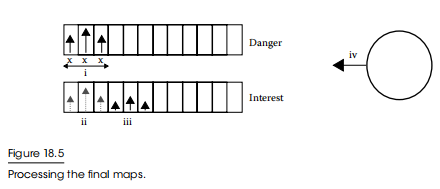
首先,我们遍历危险映射,只取最低的危险,并剔除所有有更高危险的插槽。在我们的示例中,在危险图中有一些空的插槽,因此我们的最低危险为零,因此,我们屏蔽了任何具有非零危险的插槽,如图18.5(i)所示。我们取这个掩码并将其应用到兴趣映射中,排除相应掩码槽(ii)。最后,我们选择剩余兴趣最高的兴趣地图插槽(iii),并向这个方向移动(iv)。我们移动的速度与对插槽的兴趣强度成正比;兴趣值越大意味着我们行动得越快。最后的决定是正确的决定。它是在追逐合理目标的同时保持紧急的碰撞避免——但我们是用小的、无状态的、解耦的行为来做的。这是在宏观尺度上的转向行为的承诺。
插值平滑槽位值(Subslot Movement)
您最初可能会认为上下文映射对系统的限制太大。实体总是被锁定在一个槽方向,所以你需要设定一整圈的槽位,否则你只能得到一个看起来脑子不太好(只能非常粗糙的方向移动的)的实体,这听起来很昂贵。
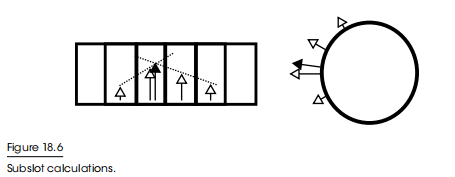
事实证明,我们可以为了性能保持少量的槽位,但运动要在一个连续的范围。一旦我们有了目标插槽,我们就可以评估它周围的兴趣梯度(即插值),并估计这些梯度应该满足的位置。然后,我们将这个虚拟插槽索引反向投影到世界空间中,产生一个要导向的方向,如图18.6所示。
在赛车游戏中使用Context Steering(Racing with Context)
上下文转向并不仅仅适用于平面上的2D实体。事实上,它很容易被移植到在一维或二维空间中做出的决策的游戏中。让我们来看看F1的上下文转向是如何实现的,以及它与传统转向示例有何不同
维度系统(Coordinate System)
我们可以假装赛车在2D空间中自由移动。在F1中,一个低水平的驾驶员系统遵循一个手动放置的标准赛道曲线,刹车的弯道和加速向下的直道。行为系统只需要管理赛道上的位置,而不是驾驶。这是通过在标准赛道曲线上的一个标量的左或右偏移。这是我们的一个维度。虽然司机会为我们刹车,但行为系统必须处理避免碰撞,所以它需要能够在紧急情况下减速。我们想要放慢多少速度,这是另一个构成我们第二维的标量。
您可以将上下文映射可视化为赛道的横截面,每个插槽代表比赛线的特定偏移量,如图18.7所示。上下文映射自适应轨道的宽度,映射的左右边缘与轨道边缘对齐。标准赛道曲线并不总是映射到同一个位置;当它在轨道上移动时,它将从地图的一边扫到另一边。在这个图和下面的图中,AI汽车是白色的。
标准赛道曲线限制行为(Racing Line Behavior)
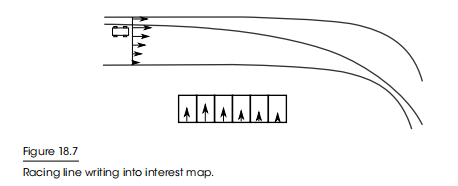
标准赛道曲线贯穿整个地图,兴趣映射列表每个槽位值的与标准赛道线距离成反比,但永远不可能为0,因为要能保证任意位置都能回正到标准赛道线,所以如果汽车被困在赛道的远边缘,它总是知道哪条路更接近比赛线。
这种行为将会在标准线附近对应的槽位写入最大兴趣值,但不会太大。能够到达赛车线应该是很好的,但我们希望有很多空间来表达其他兴趣列表的行为,这些其他行为在整个地图上仍然有重要的差异。
躲避行为(Avoid Behavior)
对于一个老司机来说,避免碰撞是至关重要的。任何类型的撞车(侧对侧或前到后)都将是灾难性的。躲避行为评估附近的所有车辆,并将危险写入与另一辆车的赛车线偏移量对应的映射中,其强度与所呈现的危险成正比,如图18.8所示。评估一辆汽车的危险是很复杂的。如果一辆车在前面,但以赛车的速度,那么你应该忽略它们——写入它们的危险只会让超车变得困难。然而,如果一辆车大大低于赛车速度,你可能需要采取规避行动,所以应该写下危险。旁边的汽车总是被认为是危险的。这是使用标准赛道曲线的一个很好的好处:行为系统可以意识到一个和自己相对静止的汽车,在这种情况下,射线投射的方法可能直到转弯后才看到它。
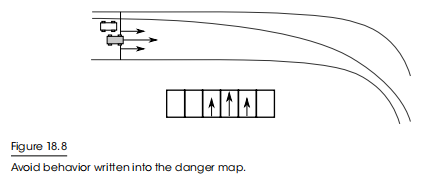
我们已经看到了上下文转向如何保证避免碰撞,但它也可以更巧妙地使用。F1在上下文映射上写了另一辆车的高度危险,但边缘的危险正在减少。这使得汽车之间的横向间距保持在最小的限度。这取决于司机的性格,更谨慎地司机会写入更高的危险值。
超车行为(Drafting Behavior)
这两种行为足以在赛道上避免碰撞,但这将使一场相当枯燥的比赛。F1还有四五种其他行为使AI更具表现力,但我们这里篇幅有限,只简单概述下超车行为。
当一辆车高速紧跟另一辆车时,就会发生超车行为。尾车不需要做那么多的工作来突破空气限制,所以它可以在不使用那么多的能量的情况下匹配领先的车的速度。在适当的时刻,多余的能量可以用来超车。
F1的超车行为评估了AI前的所有汽车,并对每辆车的“可超越性”进行了评分。快速靠近我们的汽车会得到很多分数。然后,该行为将把相应的兴趣值写到每辆车相应的赛车线偏移量处的上下文映射中,如图18.9所示。
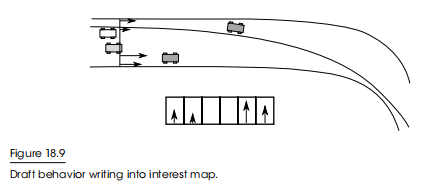
处理上下文映射(Processing Context Maps)
现在我们有了一对复杂的映射,在不同的地方都有危险和兴趣。我们如何从它变成一个真正的运动?可能有几种方法可以产生良好的一致的运动,F1就是这样做的。
首先,我们找到与汽车当前在轨道上的位置相对应的危险图的插槽,如图18.10(i)所示。
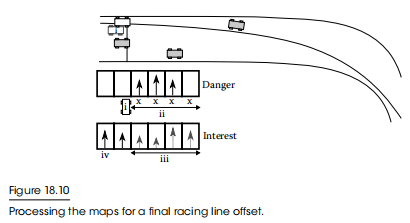
然后我们遍历上下文映射,只要下一个槽的危险小于当前值就继续。当我们无法再遍历下去时,将会剔除所有我们未到达的槽位,我们将掩码应用于兴趣映射(iii),并选择剩余的最高插槽(iv)。由此产生的运动选择了在实体的最右边的车,避免了更近的车,因为它不能不发生碰撞就能到达。
这种方法避免了进入更严重的危险,这可能代表了一个物理障碍。它也阻止我们保持在高度危险中,因为当有明显的逃跑路线时,AI会很感兴趣。一旦我们有了所有有效的动作,它就会选出其中最有趣的动作。
为了确定我们是否需要进行紧急制动,我们来看看从我们目前的槽位到最有趣的槽位遍历过程中的最高危险。如果任何槽超过某个危险阈值,我们要求刹车,强度与危险强度成正比例。我们使用一个阈值,是因为一些危险可以提供信息,而不一定是一个真正的危险,一个需要注意的正在发展中的情况,而不是一个真正的危险。
进阶技术
我们可以对所概述的简单实现进行几个改进。这些改进通常比它们的行为更容易实现和维护,因为它们在上下文映射的级别上工作,而不是单个行为组件
后处理(Post-Processing)
为了避免突变的的峰值或波谷,我们可以在行为起作用后,在上下文映射上应用一个模糊函数。由于这是一种全局效果,因此很容易进行调整,而且实施起来成本也很低。如果最近的目标在两个选择之间来回振荡,那么我们最初的转向行为例子中的追逐行为就会发生翻转。我们可以用每个行为的滞后来解决这个问题,但这增加了行为的状态和复杂性。上下文转向使我们更容易避免翻转。我们可以获取上次更新的上下文图,并将其与当前的上下文映射混合,使高值随着时间的慢慢变化而不是立即出现。
优化(Optimizations)
系统的整体复杂性取决于您的实现,但我们在这里概述的一切在内存和CPU中都是线性的,与上下文映射的分辨率成比例。将上下文映射的大小增加一倍将需要两倍的内存,而且可能需要两倍的耗时。另一方面,将地图减半将使性能翻一番。
因为即使使用低分辨率的地图,系统仍然可以提供一致的防碰撞和连续转向,所以您可以构建一个非常细粒度的详细级别控制器来管理系统负载。远离玩家的实体可以被分配给小映射列表,产生更粗糙的动作,但需要更少的系统资源。玩家附近的实体可以有更大的分辨率,这可以对地图上非常精细的细节做出反应。找到一个可以在如此微妙地调整的情况下不损害完整性的AI系统是不常见的。
由于上下文映射本质上是一维列表,我们可以使用图形编程技术进一步优化它们。我们可以使用向量内部技术(SIMD)写入上下文转向,并以chunk处理映射列表,提供一个巨大的速度。F1是这样发布的,尽管它使代码更难阅读,但回报是值得的。因为这些行为是无状态的,而且上下文映射很容易合并,所以我们可以将它们多线程或将它们放在PS3 SPU上。您还可以考虑在计算着色器中执行行为和处理。一定要进行详细的Profile,因为有些行为可能非常简单,这种解决方案的装配和卸载成本将占主导地位。将行为批处理到Job中或以面向数据的方式构建整个系统也是可能的。使用基于状态和耦合的传统转向行为想做到这一点将是困难的。
结论
转向行为在许多情况下非常有用。但如果你的游戏有一个将被玩家密切关注的个体实体,以及一个具有强大物理约束的世界(这是主要原因,因为计算出的转向行为会和物理约束冲突,但似乎我们直接把物理约束考虑进去即可?就像NavMesh那样),那么引导行为就会崩坏。对于可以用二维形式表示的游戏,上下文转向提供了强大的移动保证和简单、无状态、解耦的行为。
引用
[Reynolds 87] Reynolds, C. 1987. Flocks, herds and schools: A distributed behavioral
model. International Conference and Exhibition on Computer Graphics and Interactive
Techniques, Anaheim, CA, pp. 25–34.
[Reynolds 99] Reynolds, C. 1999. Steering behaviors for autonomous characters. Game
Developers Conference, San Francisco, CA.
Reference
 微信
微信 支付宝
支付宝



