
ProjectS中的AI转向系统(Context Steering)
前言
前阵子在处理ProjectS中的AI行为时,发现怪物AI规划出的行为很容易造成怪物重叠,这归根到底是个动态避障问题,而当前游戏AI有以下几种常见动态避障算法:
- VO : 提出速度域的概念,Velocity Obstacle 就是VO的由来。通过相对位置,并从自身出发考虑一个安全的移动方向,即避开VO区域(速度危险区)。但在移动过程中会出现抖动。原因就是反复计算安全区,当第一次避开危险区到达安全区之后,发现最佳移动方向(不一定安全,一般指朝向目标点方向)可能不再危险,就将移动方向转回来,结果发现其他寻路对象也这么考虑,也将移动方向转回来,所以第三次就又将方向转向其他方向。由此引发了移动时的方向抖动
- RVO: 在VO的基础上,每次转动方向时,只转动计算出来的变化量的一半。从数学计算角度去减少出错(抖动)概率
- RVO2/ORCA: VO与RVO都是在空间计算上来规划一个安全区域,而RVO2则是将其转化成了一个
线性规划的问题(即用一个个平面将自己与需要考虑的对象的安全区域分割开来再采取一个共面区域,这个区域就是安全区)
对于这三种算法的详细解析,可参见:GameAIPro3_Chapter19_RVO_and_ORCA_How_They_Really_Work.pdf
其中,第三种方案因为其卓越的性能和避障效果,应用最为广泛。
在尝试了动态避障算法后,发现虽然怪物重叠问题解决了,但出现了几个更严重的问题
- 怪物因追逐/攻击玩家而聚堆的时候RVO会导致长时间互相死锁(尤其是怪物AI状态不一致的时候,会让死锁出现的更加频繁,比如一些怪物AI决定直接去干翻玩家,一些决定原地待命,一些决定远程消耗玩家),原因是各个怪物朝向不同会造成一些怪物线性规划无解,只能等最外围的怪物散去时才会有解
- RVO会把怪物挤到地形里
- 由于缺少对周围环境的感知,AI会因为避障做出各种抽象的行为,比如避障把自己避进了地形死角,让玩家可以随意拿捏

当然了,只要思想不滑坡,方法总比困难多
- 。。。这个还真没想到有什么好办法能解决,毕竟是算法原理导致的这个问题
- 在行为树中对地形进行判断,涉及各种射线检测,角度检测等
- 在行为树中维护世界中的环境状态,通过各种分支让AI显得更加聪明
可以看到,要解决怪物的这些转向行为,不管是开发还是策划都需要耗费巨大的精力去拓展和维护。
当我一筹莫展的时候,窦然想起去年看的《破坏领主AI寻路与阵型 GDC》中似乎有此类问题的解决方案(悄咪咪说一句,这游戏我21年就通关了,感觉。。。画质不如原神)
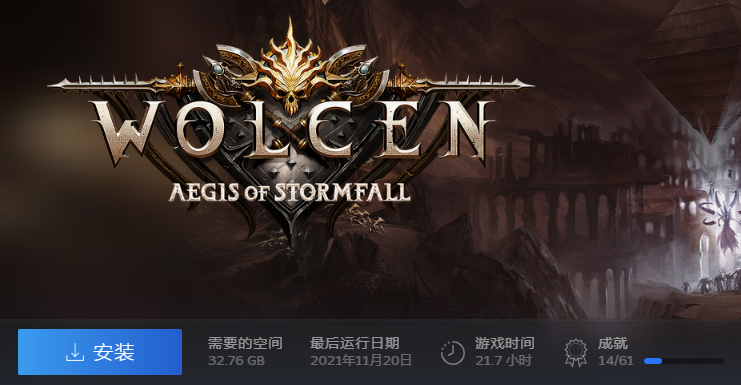
PPT中提及了一种 基于上下文驱动转向行为(Context Steering),并以直观的例子演示了ORCA和ContextSteering差别
详细了解后恍然大悟,遂有此文
Context Steering
介绍
Context Steering核心原理一句话总结就是把世界中各种环境都统一抽象为围绕AI自身的一个个向量,通过各种策略计算出最终的向量,这个向量就是AI下一步的目标朝向
只看定义太抽象了,举个例子 通过例子理解Context Steering
ORCA对比ContextSteering
下面是ORCA和ContextSteering(12方向)在10FPS决策帧率下的表现对比
其中ContextSteering设置了两个Behaviour,一个是朝着目的地靠近,一个是远离周围的对象
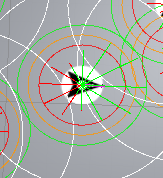

很容易发现Context Steering因为其并不太严谨的方向决策+Tick帧率限制,会有方向抖动 + 在聚堆过程中会有一定程度的穿模问题
ORCA结合ContextSteering
细想一下,ORCA其实和ContextSteering并不冲突,前者是动态避障方案,后者是综合考虑环境因素,而得出最终向量,所以我们可以把ORCA和ContexSteering相结合,让ORCA成为ContextSteering决策的一部分,在享受ORCA优秀避障表现同时,也能让AI更加智能
我们把Context Steering的Behaviours替换成ORCA,来获取最终转向量,看看结果

之所以使用同等算法的情况下Context Steering求解速度依旧比较快的原因是我们移动是12方向的,也就是没有严格按照ORCA输出的向量进行移动,即线性规划解的范围比严格的ORCA大了一些,这会造成一些小的穿模情况出现,但同时也获得了更快的求解速度
当遇到障碍
当游戏中出现障碍时,不论是地图边界还是场景中的普通障碍物,对AI来说都是一个重大的挑战,对于ORCA来说,需要将这些障碍纳入线性规划约束中,也就是需要根据障碍的形状构造geometry,传入整个ORCA系统中进行模拟,而对于ContextSteering来说,有更简单的解决方案,我们可以以AI为中心,朝周围发射射线,得到点乘值之后再翻转,就是我们想要AI移动的方向,同时可以轻松达成沿着障碍物走的目的

解决抖动
由于我们为了性能考虑,对于一个AI,只评估了12个方向,这就会造成一个问题:AI在目标不变的情况下,如果真实方向处于一个中间角度,总是会发生震荡行为
下图就是先评估到A方向,移动一两帧,又会评估到B方向,然后再次评估到A方向,如此往复
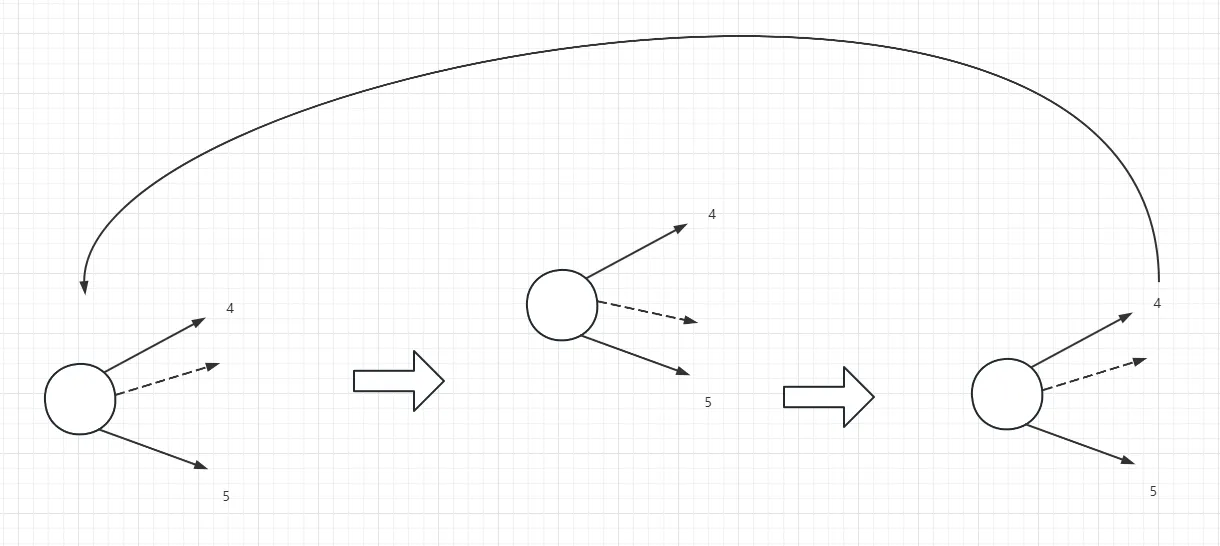
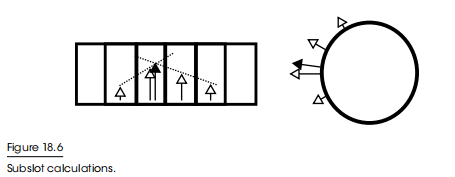
解决方式也很简单,就是我们来对最终的12方向进行梯度预测 + 升采样得到一个更加贴近真实值的点乘值,然后映射到游戏世界空间中得到最终向量
如下图所示,我们可以根据目标方向周围的向量值预估出一个更加贴近真实值的结果,预测次数越多,越准确,这样可以有效减少震荡行为
海量AI优化
由于Context Steering每一帧里每个AI进行评估时,所需的数据都是静态的,也就是无状态的,所以可以针对这个特点做并行计算优化
当前已使用基于Unity的Jobsystem + Brust Compiler进行并行计算优化
如果游戏中有海量的AI需要进行决策,我们可以把数据收集整理起来,通过StructuredBuffer将所有AI要评估的数据传递到GPU借助ComputeShader进行运算,不过cpu和gpu之间的数据传输带宽消耗也不容小觑,在使用这个方案前需要评估性能收益和带宽消耗是否值得
方案总结
看到这里,可能了解过GOAP的朋友就反应过来了,这个ContextSteering和GOAP有异曲同工之妙,两者都是把环境信息收集整理起来,通过一定的规则来得到最终的决策。
这两种方案都有一个特点,那就是可以包含任何内容,例如上文提及的方案Context Steering就包含了AStar寻路,ORCA动态避障,场景障碍躲避策略等,我们甚至可以把所有和AI转向相关的行为都转换到Context Steering,这样只需要配置好每个行为的逻辑和权重,而不需要关心其他会影响AI转向的行为,天然避免了耦合减少了维护成本,就能让系统自己得出一个最适合的方向
PS
前阵子玩最后纪元的时候,它里面的宠物行为也很有意思,当玩家往自己宠物们的方向移动时,宠物们会自动散开,以四面八方的姿态护卫玩家,想来使用ContextSteering也可以比较方便的实现

ContextSteering In ProjectS
介绍了这么多,终于可以进入正题了,那就是ContextSteering在实际项目的落地,首先确定下大体架构
乍看之下没有什么问题,实践起来小问题不断,具体来说有以下几点:
-
抖动问题
-
由于AStar的出的路径点基本上都不在一条直线上,而ContextSteering每次决策输出的是一个向量V,这就会导致这样一个问题:假设当前寻路结果有三个路径点依次为:A,B,C,并且此时玩家P处于AB之间,在不考虑其他环境因素的情况下,得出的向量V是A->B,如果玩家P移速过快,那么这一帧的末尾就会越过B点,处于A->B的延长线上,从而导致逻辑错误
-
出于性能考虑,我们会把ContextSteering的Tick频率设置在一个相当低的水平,比如10FPS次,如果我们逻辑帧是30FPS的话,相当于每两次ContextSteering Tick中有2帧是忽略环境因素,在用上一次的决策向量在移动的,这会导致两个问题:
- 各个AI单位的穿模,不过有ORCA的保障,其实不会太严重
- 进入原本不该进入的地形中,从而导致AStar寻路不再能生效,因为Recast烘焙的网格是静态的,必然已经排除了地形,所以如果此时其余的决策Behaviour依旧计算不出一个能让AI脱离地形的向量,那么这个AI就会一直卡在这个地形中
接下来就依次解决这几个问题
解决抖动
收到GameAIPro中图示的启发,对算法进行了改良
一开始我尝试我认为更加科学的方法:不再直接通过梯度获取结果,而是将每个栅格平均划分,梯度预测结果将会落在划分的栅格内,这样可以得到更加平滑,贴合变化趋势的向量结果
根据梯度预测,对目标向量周围做升采样,默认升采样次数4,我们默认ContextSteering分辨率为12,即间隔30°,升采样4次后间隔就是 30°/(2^4) = 1.875°,再加上我们的双缓冲机制平滑,基本上可以做到无感知,初始采样个数5(包含maxIndex),即maxIndex后两位+maxIndex+maxIndex前两位。
看起来很棒,但其实会有一个问题,随着不断细分,在这种均匀变化的情况下,会无限逼近原本的maxIndex,而细分次数不够,又达不到预测的效果,导致整个预测方案失去意义
所以最后还是选择了原本GameAIPro的做法,并且会对MaxIndex的左右两边各进行一次预测,再进行对比从而得到更加合理的结果
需要特别注意的是,这种预测只是尝试对原本的结果进行还原,归根到底没办法预测到和原本值一致的程度,尤其是遇到均匀变化的数值时,因为投影操作本身是非线性的,所以对均匀变化的数值,预测准确度相当有限,所以最好的做法是增加分辨率,比如从12到48,96。。。
整个过程如下图所示
更加精确的AStar Nav Point
这个处理起来其实比较简单,我们只需要根据人物速度计算出真正能到达的位置点作为下一个目标点即可,还是以上面的AStar为例,它会变成这样
因为是一帧(ContextSteering中的一帧)内的位移,所以这一帧末尾AI就已经在目标位置了,不会出现穿越地形和逻辑位置错误的问题
当然了,这是在没有其他环境因素干扰的情况下,如果AI要躲避其他AI和障碍,那么真正的目标朝向就可能不会是图中所标识的那样,而是会是下图中的P’‘
当然,这是预期中的避障行为,脱离AStar轨道自然也在情理之中,不过我们需要定期重计算AStar路径,来应对这种脱离AStar轨道的情况
此时又会出现一个问题:当此帧结束后,下一帧我们目标点又是哪里,依旧是B点,还是C点?
因为AI完全有可能由于各种环境因素导致位置偏差到一个任意一个位置,例如上图中的P''',P’‘,由于我们是2D空间的决策,所以可以约定一个抵达规则:每次ORCA这个行为预测后,会记录此次预测结果,如果在MoveComponent执行移动时发现移动方向和预测结果一致,就认为抵达预测的目标点,同时会设置抵达的目标点信息(例如,ORCA预测会抵达P‘’点,如果MoveComponent执行移动时发现移动方向就是朝P‘’移动,就认为AI这一帧一定会抵达P‘’点),如果不一致,说明有其他因素影响了AI移动,此次预测失败,下次移动依旧是用上一次的起始点点作为预测起点
对于最后一个路径点,我们需要特殊判断,一般我们会指定一个容忍范围,比如AI处于最后一个路径点x米内都算抵达,这样可以达成怪物围绕玩家成一个圈的效果
解决其他AI占用AStar路径点时导致的抖动
如果一个AI B正好处于我们AStar路径点上,就会和ORCA冲突,因为一方面想要抵达目标点,一方面又要由于ORCA远离目标点,当A,B都处于移动状态时,就会出现抖动的情况。
解决方案就是出现这种情况时不进行动态避障,允许让它穿模
1 | // 判断是否有Agent恰巧在路径点上,如果是,则强行穿过 |
更加严格的地形穿模检测
最好的方式就是为地形添加刚体Collider,可以阻止穿模,其次就是新建一个Behaviour,用于处理地形穿模避障
Reference
 微信
微信 支付宝
支付宝



