(译)Forward Plus Bringing Deferred Lighting to the Next Level
在网上鲜少有能全面,具体介绍Forward+渲染管线的文章,所以抽空翻译下这个2015年的PPT,分享出来
摘要
这篇论文介绍了Forward+,这是一种通过剔除和仅存储对像素有贡献的光源来渲染许多光源的方法。Forward+是对传统的Forward渲染的扩展。利用GPU的计算能力实现的light-culling模块被添加到渲染管线中,用于创建有效light-list;该列表传递给最终的渲染着色器,该着色器可以访问有关光源的所有信息。尽管Forward+增加了最终着色器的工作量,但从理论上讲,它与compute-shader-based的延迟光照相比需要更少的内存带宽。此外,它避免了延迟技术的主要缺点:即对材质和光照模型的限制。
本论文进行了实验以比较Forward+和延迟光照的性能。
PS:参考Forward框架的逆袭:解析Forward+渲染 的内容,TBDR和Forward+内容对比:(注意此处的TBDR不是指移动平台的TBR架构,而是一种渲染流水线方案)
TBDR:
- 生成G-Buffer,这一步和传统deferred shading一样。
- 把G-Buffer划分成许多16×16的tile,每个tile根据depth得到bounding box。
- 对于每个tile,把它的bounding box和light求交,得到对这个tile有贡献的light序列。
- 对于G-Buffer的每个pixel,用它所在tile的light序列累加计算shading。
Forward+
- Z-prepass,很多forward shading都会用这个作为优化,而在forward+中,这个变成了必然步骤。
- 把Z-Buffer划分成许多16×16的tile,每个tile根据depth得到bounding box。
- 对于每个tile,把它的bounding box和light求交,得到对这个tile有贡献的light序列。
- 对于每个物体,在PS中用该pixel所在tile的light序列累加计算shading。
从这里可以看出,前两步与Tiled-based deferred shading大同小异,但只需要Z-Buffer,而不需要很消耗带宽的G-Buffer(G-Buffer最小也要32bit color + 32bit depth)。第三步是完全一样的。第四部由于用了forward,可以有forward的各种好处:
- 复杂材质
- 支持硬件AA(虽然我一直认为硬件AA多算了很多东西,是一种巨大的浪费)
- 带宽利用率高
- 支持透明物体
概述
近年来,延迟渲染在实时渲染中变得越来越受欢迎,尤其是在游戏领域。延迟技术的主要优势在于能够使用多种光源、将光照与几何复杂性分离以及可管理的着色器组合。然而,延迟技术也存在一些缺点,比如材质种类有限、更高的内存和带宽需求、处理透明物体的困难,以及缺乏硬件抗锯齿支持[Kap10]。材质的多样性对于实现真实的着色效果至关重要,而这对于Forward渲染来说并不是问题。然而,正向渲染通常需要设置少量且固定的光源,以避免PS的ALU消耗过大,并且需要CPU管理光源和物体。此外,由于当前游戏主机(例如XBox 360)上的昂贵的动态分支性能,延迟渲染变得更具吸引力是在情理之中的。
近些年的GPU硬件的计算能力得到了很大提升,这使得使用Forward方法进行大量光源渲染变得可能,即使如此,在片段着色器遍历所有光源进行着色的方法还是代价过高。
我们提出了Forward+:一种通过剔除和仅存储对像素有贡献的光源来进行渲染的方法。光源在最终的着色器中逐个进行计算。通过这种方式,我们保留了正向渲染的所有优点,并获得了以大量光源进行渲染的能力。
相关工作
Foward在进行着色时可以使用的光源数量存在严格的限制[AMHH08]。延迟技术克服了这一问题,并且在游戏主机等设备上变得越来越受欢迎。
延迟渲染需要导出存储屏幕空间光照所需的所有几何信息的GBuffer从而使得内存压力很大。
延迟光照将光照计算和材质计算分离,以减少内存带宽。Andersson [And11]利用GPU的计算能力实现了延迟光照系统。从理论上讲,该方法通过减少内存带宽可以在现有的延迟技术中获得最佳性能。
基于灯光索引的延迟光照采用了略有不同的方法,它存储灯光索引而不是叠加灯光分量[Tre09]。它减少了GBuffer导出的成本,但在最终着色过程中需要读取更多的数据,相比之下需要比延迟光照技术更多的数据。这种方法有一些限制,例如每像素的光源数量具有预定义的最大容量。Forward+在不受其限制的情况下学习了这种方法的概念,并通过使用现代GPU的灵活计算能力进一步减少了内存带宽。
方法
Forward+通过在最终着色之前添加light-culling阶段扩展了正向渲染管线。该管线包括三个阶段:深度预处理、light-culling和最终着色。另一个修改是对光源数据结构的调整,它必须存储在线性缓冲区中,着色器可以从中进行访问,以进行light-culling和最终着色。深度预处理对于正向渲染是可选的,但对于Forward+来说,它是必不可少的,以减少最终着色步骤中的像素Overdraw(这对Forward+来说尤其昂贵)。如果将深度预处理与延迟技术中使用的GBuffer预处理进行比较,延迟技术中会导出全屏几何信息,而正向渲染中的深度预处理更便宜,因为它只填充深度缓冲区。
light-culling
light-culling阶段类似于延迟光照中的叠加灯光分量。但light-culling不是计算光照分量,而是计算重叠像素的light-index列表。可以为每个像素计算light-list,这对于最终着色来说是更好的选择,但如果考虑整个渲染管线的效率,这种方法并不高效。
最重要的问题是内存占用和light-culling阶段计算的效率。因此,屏幕被分割成tile,并且light-index是根据每个tile来计算的。尽管tile化可能会为tile中的像素增加错误的light-index,但它大大减少了内存占用和计算量。light-index缓冲区的内存大小和最终着色器的效率是一种权衡。通过充分利用现代GPU的计算能力,light-culling可以完全在GPU上实现,正如第4节中所详细描述的那样。因此,整个光照管线完全在GPU上执行。
着色
light-culling创建了覆盖了每个像素的light-list,而最终着色则遍历light-list,并使用存储在每个光源的信息来进行材质计算,例如光源位置和颜色。这些信息在使用延迟技术最终着色时是不可用的。现在,可以将每个材质实例的信息存储并访问到线性结构化缓冲区(structured buffers)中,并将其传递给最终着色器。因此,由于光积累和着色同时发生在一个地方,并且具有完整的材质和光照信息,因此渲染质量的所有限制都已经被消除。使用复杂的材质和更精确的光照模型来改善视觉质量不受其他限制,除了GPU计算成本,这在很大程度上由覆盖单个像素的光源数量×材质成本×光照模型成本所决定。使用这种方法,高Overdraw可能会降低性能;因此,深度预处理对于最终着色的成本最小化至关重要。
light-culling实现
Forward+渲染管线可以重用大部分现有正向渲染管线的代码,因为它主要是对其进行扩展。compute-shader-based的光源剔除是该技术的重要补充。由于当前GPU和图形API的灵活性,光源剔除可以以多种方式实现,每种方式都有其利弊。本节描述了两种完全在GPU上运行的实现方法。这些方法按tile构建light-list。虽然它们也可以通过运行额外的kernel来按像素构建light-list,但这会增加计算时间和内存占用。
收集法
这种方法使用了一种收集(Gather)的方式,在单个computer shader中构建light-list,类似于[And11]。它对每个tile执行一个线程组(Thread Group)。通过使用tile的屏幕空间范围和像素的最大和最小深度值来计算tile的视锥体。kernel首先使用线程组中的所有线程将光源读取到本地寄存器中。然后并行检查光源与tile视锥体的重叠情况。如果光源有重叠,线程将使用本地原子操作将光源累积到线程本地存储(TLS)中。在收集完所有与tile重叠的光源后,它使用所有线程将光源刷新到全局内存中。这种方法在光源数量不是太大时简单而有效。但当光源数量非常庞大时,可能需要考虑使用查找(Scatter)方法。
映射法
首先,它计算出每个光源与哪个tile重叠,并将light-index和tile索引数据写入缓冲区。这是通过执行每个光源一个线程来完成的。此时缓冲区的数据(按light-index排序)需要按tile索引进行排序,因为我们需要每个tile的light-index列表。我们使用基数排序(radix sort),然后运行内核来找到缓冲区中每个tile的起始和结束偏移量。
结果和讨论
Forward+是使用DirectX11实现的,Fig. 1 (a) 是使用Forward+的AMD Leo演示的屏幕截图。由于该方法允许使用任何表面着色器,因此不限制光照和表面材质。演示中使用的一个材质示例是金属着色器,其中对贡献到像素的所有光源进行了物理上准确的效果评估。

然而,天下没有免费的午餐。我们为了更好的渲染质量愿意付出怎样的代价?为了对Forward+进行详细分析并进行比较,我们实现了compute-shader-based的延迟光照管线,该管线不写入GBuffer[And11]。这种实现的好处在于它通过使用computer shader一次读取和写入Framebuffer,从而节省了内存带宽。因此,从理论上讲,它在内存带宽方面是最佳的,而内存带宽是标准延迟技术的一个缺点。
我们比较了Forward+和延迟渲染在管线的三个步骤中的理论内存带宽。在光源剔除的实现方面,选择了收集法,因为光剔除与延迟光积累类似。表1比较了这些方法的理论内存带宽。延迟渲染在GBuffer预处理阶段将所有数据压缩为要写入的单个float4渲染目标。而Forward+不会写入全屏光积累缓冲区;相反,它只在光处理时写入每个tile上重叠的光索引。在大多数情况下,光索引的数据大小远远小于完整的帧缓冲区。然而,增加了光剔除阶段会增加最终shading时的内存读取:Forward+必须读取所有重叠的光索引和光信息,而延迟渲染技术只从光积累缓冲区中读取float4。通过将Forward+的总内存带宽减去延迟渲染的总内存带宽,就可以得出, 现在假设 ,则 , 我们发现如果光源是点光源(L = 8,包含位置、半径和颜色),并且每个tile的平均光源数M小于 ,则Forward+需要比延迟渲染更少的内存带宽()。总的来说,对比计算基础的最低内存占用的延迟光照技术和Forward+,在理论上,没有任何延迟渲染技术能够在内存带宽方面打败Forward+。

为了确认这一分析,我们建立了一个包含 3,072 个散布在空间中的光源的演示场景,如图2(a)所示,并比较了这两种方法的性能。我们使用了 8×8 的tile大小。图2(b)是每个tile上光源数量的可视化。tile与模型边缘重叠的原因是视锥在深度方向上更长;因此,它会表示处与整个视锥重叠的光源。为了改善这个问题,必须检测每个视锥中的空白空间。然而,一个tile中可以有任意数量的深度层。一个复杂的空白空间检测并不值得。使用空间细分而不是二维细分可能会解决这个问题,但这需要更多的内存和ALU操作。

在图3中,Forward+(H)和Deferred(H)是在AMD RadeonTMHD 6970上的渲染时间。我们测量了表1中的预处理、光处理和最终着色的计算时间,包括内核调度成本和GPU管线刷新开销。测得的时间不是纯粹的GPU处理时间,但比较是公平的,因为两种测试条件相同。结果证实了理论内存带宽消耗的分析:Forward+在预处理和光处理方面更好,而延迟渲染在最终着色方面更好。
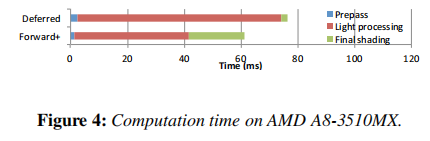
总体而言,Forward+更快。我们还通过降低GPU的内存时钟速度来测试,以模拟具有较低内存带宽的GPU。如图3中Forward+(L)和Deferred(L)的比较所示,Forward+和延迟渲染之间的差距变大,因为延迟渲染需要更多的内存访问。将来,GPU可能会增加ALU/内存带宽比,因为增加ALU单元比提高内存带宽更容易。这个实验表明,Forward+在具有该规格的GPU上是有前景的。我们在AMD A8-3510MX上进行了另一项测试,该处理器集成了AMD Radeon HD 6620G GPU。图4中的结果证实了对集成GPU上的Forward+的理论分析,与离散GPU相比,集成GPU的内存带宽更有限,SIMD单元更少。一些移动或集成GPU采用基于tile的渲染。具有tile光剔除的Forward+非常适应这种渲染架构,因为它可以减少最终着色时读取光列表的成本。

在本文中,我们没有调查tile大小如何影响性能,这取决于tile大小以及许多其他因素,如场景的几何复杂性、光源数量和光源的最大影响距离等。自动找到场景的最佳tile大小可能是未来一个有趣的研究课题。
结论
我们提出了Forward+,这是一种渲染方法,它在传统的前向渲染管线中增加了基于GPU计算的光剔除阶段,以处理大量光源。它让我们摆脱了延迟渲染技术的限制,并通过结合前向和延迟技术的优势,实现更好的渲染质量。Forward+在理论上需要的内存带宽比compute-shader-based的延迟光照少。
我们进行了实验证明,Forward+表现优于内存占用最少的延迟光照技术。
作为未来的工作,由于最终着色的自由度,我们可以探索许多可能性。一个例子是通过对光源进行局部短射线投射,从场景中所有光源计算阴影。
引用
[AMHH08]
AKENINE-MOLLER T., HAINES E., HOFFMAN N.:
Real-Time Rendering, 3 ed. AK Peters, July 2008. 2
[And11]
ANDERSSON J.: DirectX 11 Rendering in Battlefield 3.
Game Developers Conference (2011). 2, 3
[Kap10]
KAPLANYAN A.: CryENGINE 3: Reaching the speed of
light. ACM SIGGRAPH 2010 Courses (2010). 1
[Tre09]
TREBILCO D.: Light indexed deferred rendering. In
ShaderX7 (2009), Charles River Media. 2
 微信
微信 支付宝
支付宝