《守望先锋》回放技术-阵亡镜头、全场最佳和亮眼表现
前言
《守望先锋》2017 GDC系列的分享前几年给了我很多帮助,尤其是kevinan大神的翻译更让我受益良多,如今我再想温习一下相关技术却发现很多网络上的文章图片都已经坏掉了,故在此收集网络资源发布重置版,当成备份。
重制版内容:新增多级标题,方便分块阅读,部分图片已由本人重置,一些必要的地方我录制了Gif图,方便观看。
全系列链接:《守望先锋》GDC2017技术分享精粹重制版总目录
原视频链接:https://www.youtube.com/watch?v=W4oZq4tn57w&ab_channel=GDC
设计目标
那么回放系统的概要设计(high level design)目标是什么呢?
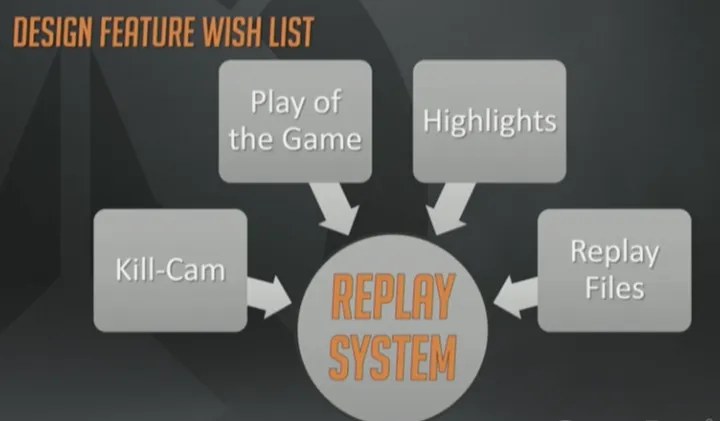
这次分享的标题就预示着必须给出答案,对吧?概要需求是创建一个单一的中央系统,能够支持阵亡镜头、全场最佳和亮眼表现,除此之外我们还特别需要能够生成录像文件,在开发期间可以用来做内部调试。
下面开始深入介绍每个议题。
每次玩家死亡时,游戏里就会显示临死前几秒钟的――大部分情况是以凶手(killer)视角来看的――死因及死亡过程。阵亡镜头可以帮助玩家理解他们是怎么死的,以及为什么会死,有一定的教学作用。
上面展示的视频例子(狂鼠被半藏杀死的例子)中,可以看到死亡过程中的几个关键节点,玩家死亡时有3件值得注意的事:玩家尸体布偶化(ragdoll,也叫布娃娃,专用术语,全称Ragdoll physics,是用在电子游戏的物理引擎中代替传统静态动画的可变性角色动画系统),方便判断死亡方式(译注:估计说的是炸死、摔死还是射死等);游戏镜头朝向凶手;凶手轮廓描边,即使隔着墙也可以看见,从而使你查看得更加清楚(译注:这一点在视频中没有得到展示)。
我们会以淡入的方式进入阵亡镜头,展示死前一段时间以及死后几秒钟的画面。你能看见自己的尸体布偶,然后明白自己是怎么死的。
网络同步模型概览
闲话少说,咱们接着讲网络同步,主要包括设计回放系统的常规模型,以及如何交互。
回放系统不可避免地要受限于模拟(simulation,游戏逻辑 渲染)模块和网络模块。
Glenn Fiedler(译注,TitanFall的开发)那个很棒的系列博客(译注,该系列博客地址http://gafferongames.com/networking-for-game-programmers/ ),早已经把网络同步机制总结为三类了:
- 确定性帧同步(deterministic lockstep),常用于竞速游戏或者星际争霸2、魔兽争霸2这样的即时战略游戏;
- 快照插值(snapshot interpolation),FPS经典同步模型,《Quake》最早采用,后续众多FPS在之上做了改进;
- 状态同步(state synchronization),有点像是快照插值的改进版,也是Overwatch所采用的。
注意我的幻灯片下方列出了一些参考文章,正是这些文章启发了我们,设计出了我们自己的同步策略:
- GDC2015 Physics for Game Programmers : Networking for Physics Programmers
- I Shot You First: Networking the Gameplay of HALO: REACH[David Aldridge]
- The TRIBES Engine Networking Model [Mark Frohnmayer]
确定性帧同步
快速浏览一下这些技术。第一个是确定性帧同步,左边有4个客户端,都连接到同一个服务器上。服务器也可以由其中的一个客户端来兼任。简单起见我们假定有个专属的某某云服务器。

客户端接收玩家输入并上报给服务器,服务器在接收到全部输入以前,保持锁定当前帧。当全部客户端的输入都上报完成时,服务器才开始模拟游戏进程。

处理好全部输入以后,服务器批量打包所有指令,并转发给全部客户端。

然后客户端基于刚刚收到的转发指令,开始各自模拟游戏过程。代码处理得当的话,每个客户端都会得到相同的结果,看上去很美妙。
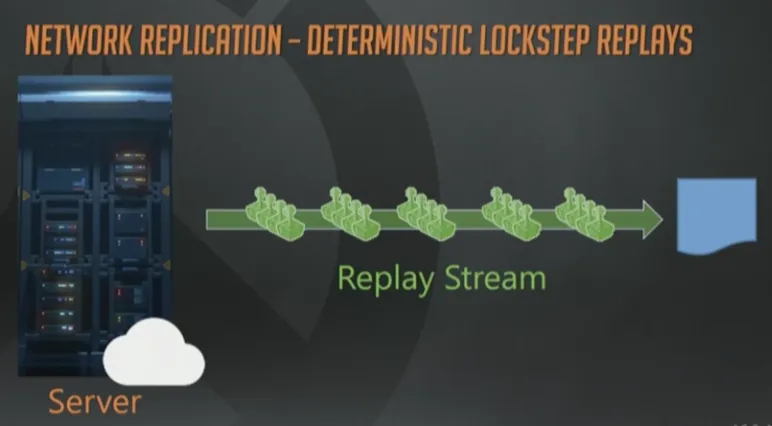
基于帧同步实现一个回放系统很方便,只需要记录整个输入流即可实现回放。而且输入通常很容易压缩,所以数据量也不大。

确定性帧同步,虽然架构简单,但是也有一些缺陷。它的模拟过程需要严格一致,同一帧内,相同的输入集合在每个客户端必须产生同样的输出才行。
如果做不到这一点,客户端之间就会产生不同步,会对当前处于何种状态各执一词。例如对浮点数依赖程度很高,而浮点数运算很难做到严格一致,尤其在不同的平台架构下更是如此。 一个简单的打印驱动失灵,就能在中断控制器上改掉浮点数精度设置,从而使模拟过程偏离轨道。而且这一点的确会发生。

维护一个确定性的模拟过程,除了代码逻辑上的工作以外,还有一个问题就是多玩家联网时产生的。
“等待全部玩家的输入”意味着,任何一个停滞的玩家都会破坏模拟过程的及时性。游戏里玩家数量越多,这个风险越高。简单计算一下,假设一个5分钟时间的游戏,每个玩家卡顿的概率是2%,4个玩家就会有8%的可能性,玩家多达12个时,已经是22%了。
我本应该画个图表来说明这一切的。

上述缺陷都是可以克服的。 通过遵守合适的编程规范就可以开发出并维护一个确定性模拟系统的,我们开发过很多这样的游戏,这样做绝对可行。 或者可以耍点小聪明来隐藏缺失玩家输入引起的卡顿,例如你可以用倒带法(rewind)重新模拟或者维护一个预测(predict)窗口。
Overwatch最终没有选择确定性帧同步方案,原因如下:首先,我们不希望程序员和策划的因为偶现的不确定性而产生心理负担;除此之外,要支持中途加入游戏也不简单。模拟操作本身就已经很耗了,如果5分钟的游戏过程,每次都需要重头开始模拟的话,计算量太大。
最后,实现一个阵亡镜头也会很困难,因为需要客户端快照以及快播机制。按理说如果游戏支持录像文件的话,快播自然就能做到,不过Overwatch并没有这一点。
快照同步
那么下一个选项就是“快照同步”了,与确定性帧同步相类似,也是客户端接受玩家输入然后上报给服务器。然而,这个模型里的服务器是可以忽略某个玩家输入缺失而继续向前模拟的。

这里不会转发输入操作给全体客户端,取而代之的是服务器模拟游戏世界,不停地生成整个世界状态的瞬时快照。

然后服务器会把快照下发给客户端。客户端根据这些快照来更新各自的世界状态,通常会用“插值”方法在两个相邻的快照间做平滑(译注,关于插值,可以参考Source引擎,解释的比较权威)。

这种方式运作良好,概念也很简单,同时避免了帧同步模型中的确定性和卡顿问题。事实上,稍加改造,再结合一些压缩,就能得到一个比较可靠地模型了。
差异计算过程比较耗费资源,你可以分摊快照成本或者“增量”(Delta,下文中会多次出现,并直接用英文单词)压缩,这样对于多个客户端来说,只需要处理一次就好了。
如果你担心有人作弊,你就需要维护一些客户端不应该看见的对象的实时数据,然后只下发客户端能看见的东西。

基于快照同步实现回放系统的话,十分简便。从一个完整世界状态开始,更新每帧时添加差异就好了。广义上讲,这个方案就是依赖新技术的游戏客户端如何播放录像文件的问题。客户端要做的仅仅是把网络游戏数据序列化到硬盘上。
这套架构实现阵亡镜头同样很简单。 你已经有全量的快照了,对吧?所以只需要维护一个环形缓冲区,保存过去时间点到当前时间之间的世界状态历史,然后重播就行了。注意到我把这里快照(图片)的大小做成不同(译注:指的是上图中Replay Stream线上的4副图)的,你可以图片大近似想象成每一帧的序列化数据尺寸。有一些帧变化的少,所以尺寸就小。

这个例子里,我同样使用了不同尺寸的管道(代表数据量的多少)。快照尺寸就相当于快照同步模型的阿喀琉斯之踵,它限制了在每一帧内,世界状态变化的程度和次数。需要同步的东西越多,初始快照尺寸就越大。帧与帧之间变化越多,Delta就越大。变化越多意味着需要的比特位就越多,而比特位需要消耗宝贵的带宽资源。
对于一个高频互动的游戏,如果想要在低带宽环境下正常运作,最终能依靠的就只剩几种主流的同步模式了。
状态同步
基于状态的同步。 这一页幻灯片与之前的一模一样,客户端上报输入,服务器执行模拟。
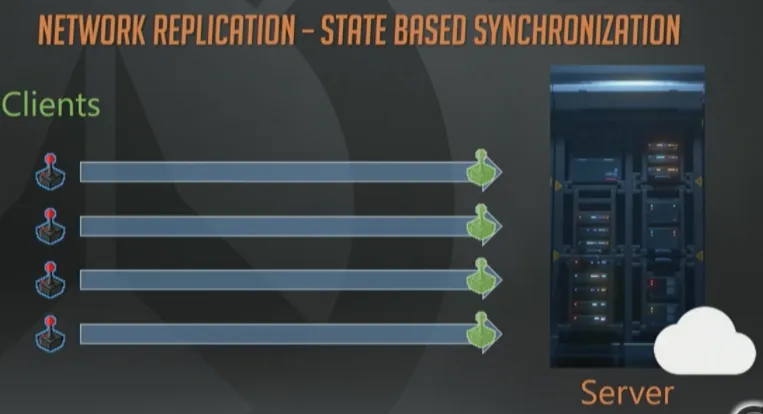
与快照同步模型相反,服务器不会为全体客户端生成单一更新,而是给每个玩家发送纯手工定制、公平贸易换来的、原生态的数据包(众笑)。

那么,当我们谈论“世界状态”(world state)时,是在谈论什么呢?
我想说的是,任何用来表达游戏世界所需的必要状态。可以想象一个代表个体位移、旋转、血量、动画参数和武器发射状态等等的分类数据表。在快照同步模型中,客户端会收到全部状态数据并“原子化”执行一遍。

基于状态的序列化,会把世界快照分解成更小的、原子的数据块。因为每个客户端收到的数据都是订制的,我们可以基于客户端相关性来设置更新的优先顺序。这样就能够基于客户端的实测带宽来智能调整数据流了。
上图的例子里,有个客户端收到1个数据包同时包含了大锤和法拉的更新信息。另一个客户端则收到了2个数据包,其中1个是大锤,然后1个是法拉的信息。这里最重要的一点就是对象可以独立更新,每个客户端的数据都是分别订制的。
客户端网络状况参差不齐的情况下,这种模型就是最灵活的,不过实现起来也是最复杂的。这就是Overwatch的实现方式。
现在咱们深入了解一下Overwatch里是如何做到稳定的网络同步的,以及回放系统在这个同步范式下是如何实现的。
专业术语介绍

先介绍几个术语,Overwatch使用的是ECS架构:实体是由组件组成的,由System负责更新(译注:关于ECS请读者参考另外一篇分享:GDC2017 Overwatch Gameplay Architecture and Netcode)。
有些System是序列化过程的参与者(participants),它们负责同步游戏的某些方面(aspect)给接收者(receivers)或者复制目标(replication targets)。接受者一般就是需要接收数据的活跃玩家或者观战者(spectator)。最后,复制目标会收到关于其他实体的更新消息。
通常我会把这一切简言之为:参与者把网络相关实体数据打包并发给接收者,这些实体就叫“主体”(subject)。
顺便给我的同事们打个广告,如果你对Overwatch游戏架构、网络同步的其他方面也感兴趣的话,Tim Ford和Dan Reid的分享刚好与我的互补。他们的已经结束,可以在GDCVault.com上收看(译注:另外一篇GDC2017 Networking Scripted Weapons and Abilities in Overwatch在此)。
状态同步的具体示例
基础机制
下面来个具体点的例子,假定你正在控制法拉(Overwatch英雄之一)你跳了一下然后飞起来准备低空轰炸,这个消息是如何发给其他玩家的呢?

当你开心地按下按钮,客户端预测就开始了,同时(译注:原文是then,但其实这个操作不需要考虑前后顺序的)把这个命令上报给服务器。
服务器收到连同你在内全部玩家的输入后,一个经过”官方批准”的模拟过程就开始了:一些实体移动了;一些英雄倒下了;抛射物爆炸了,简直就像开Party一样,美妙极了。

最终的每个变化和事件,我们统称为Delta,例如”位置变化”就是个(服务器上的)Delta。
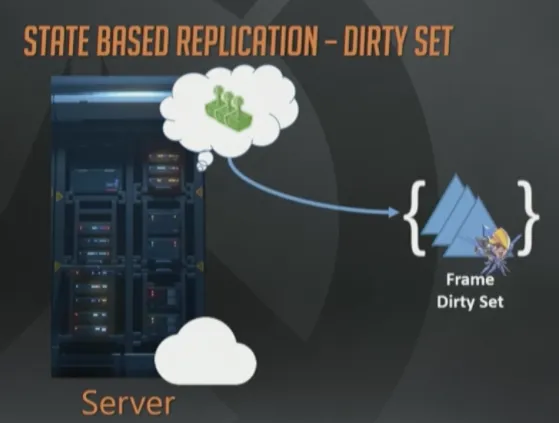
在服务器端,我们会累积所有对象状态的变化,然后保存在一个临时的“每帧脏数据集合”(per frame dirty set)里。可以简单地认为它就是个字面意义的数学概念的集合,包含所有在那一帧发生改变的实体的ID。
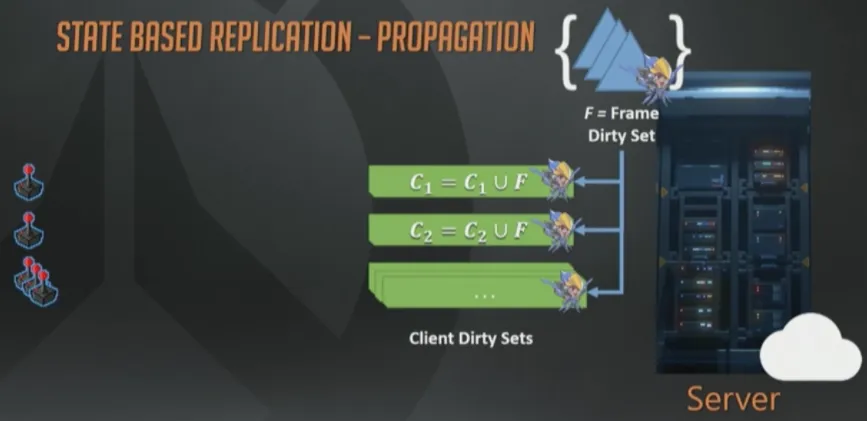
那如何把这些状态转发给客户端呢?我们对每个已连接的客户端也维护了一个“脏集合”(译注:应该指的是C1, C2…作者没有交代这些集合是如何生成的,不过从下文的C1=C1-P可以推测出来)。这一页幻灯片右上方的F是当前帧脏集合。每帧结束时,所有接收者的脏集合会与帧脏集F合并(还是数学上的并集概念),这样数据打包时就可以只包含那些该客户端真正需要的实体集合了。在帧结束时,这些操作都做完以后,帧的脏集会被清空,下次更新(tick)时,一切重头开始。
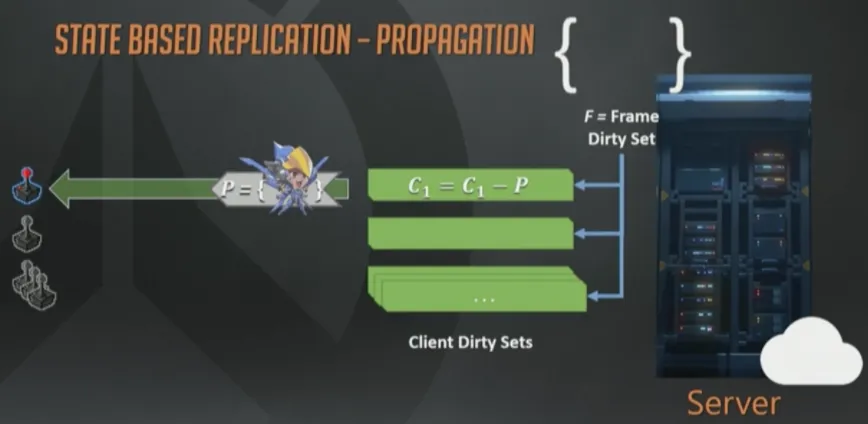
在同一个更新周期(tick)的后期,脏状态(译注:C1,C2…)会被序列化成一个数据包,通过“网线”(这个年代到处都是网线)发给接收客户端。
数据一旦被序列化,就会从脏集合中移除(C1=C1-P)。带宽是稀缺资源,所以我们不会使用原生的状态数据,而是维护了一个经客户端确认收到的状态数据的历史记录,这样就可以进行“增量编码”来改进带宽使用模型,也就是减少带宽的占用。
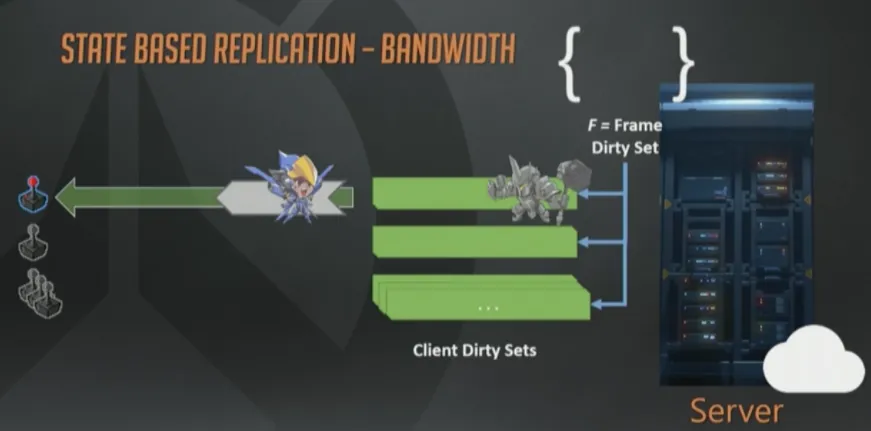
对于大多数帧,我们都有足够的带宽来序列化所有数据。即使不够也没关系,这个例子里,只更新了法拉的状态,因为客户端带宽不足,无法容纳大锤的数据了。无论如何,接收者脏集合都会把它保存下来,最终会在将来的某个时刻成功序列化到某个下行包里。
这就是状态同步模型的一大优点,可以基于带宽质量来调整下行数据大小。

网络协议我们用的是定制的UDP。众所周知,UDP是不可靠协议,意思是说一个数据包可能会成功达到目的地,也可能到达2次,或者乱序到达。这都没关系,我们自己设计的协议可以感知丢包并在必要时重传脏数据。
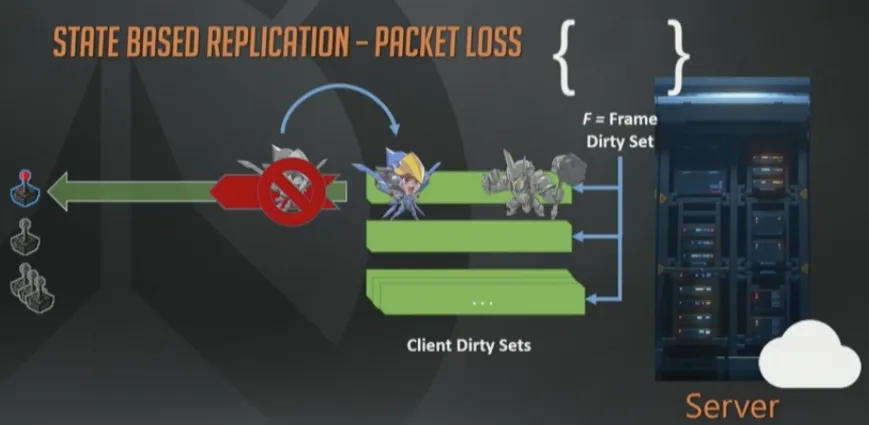
丢包发生时,只需要简单的把这个数据包合并回脏状态集合,留待将来重传即可。在未来的包里,我们可以把法拉移动这件事,连同该帧其他事件一起重传,例如大锤开盾。
注意, 如果在首次移动包发送完与收到丢包通知之间,法拉再次移动了,那么无需重传旧状态,我们会把新的移动状态序列化到旧状态数据里。

新玩家进入游戏的追帧
现在聊一下新加入游戏的玩家,是如何追赶上最新的世界状态的。
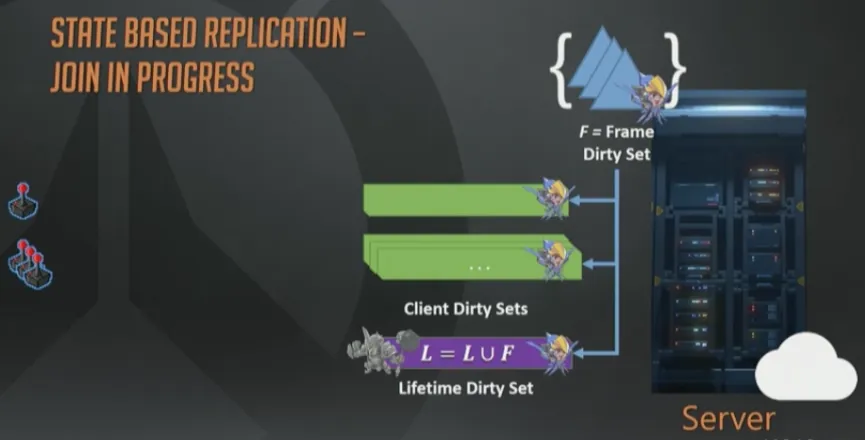
我们在服务器上维护了一个“永久”(lifetime)脏状态集合L,是个全量的脏状态集合s。也就是服务器上所有曾经变脏的状态的“全集”。接下来的事情,你肯定能猜到。

你猜对了,新玩家连上后,我们会把它的初始脏状态集合设置为“永久”脏集合L,这里的设置就是字面意义上的赋值。正常的打包流程最终会把所有变化都下发给这个客户端直到它赶上最新的进度。
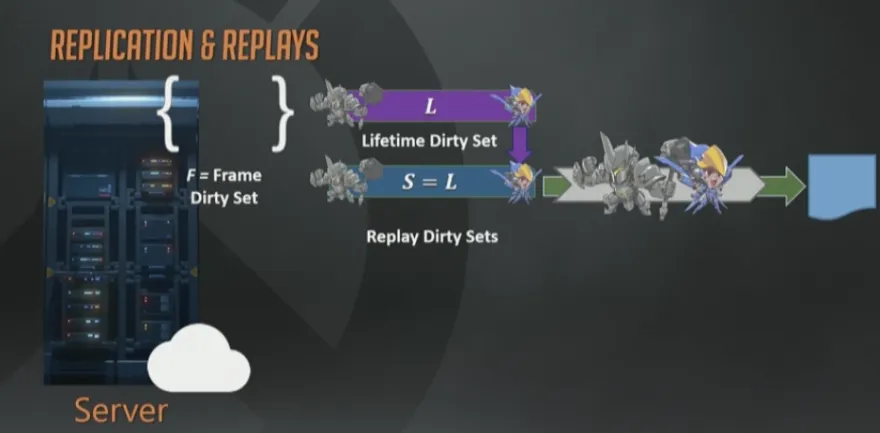
一切都很顺利,但是差点忘了, 我们是要做“回放”而我却一直在讲网络序列化。可以把回放数据流近似的认为就是正常游戏的网络数据流,仅仅是接收者有点区别而已,回放系统的接收者叫做“回放快照接收者“(replay snapshot receiver)。
所以实现回放系统的一个方式(并非最好,后面马上优化)就是,在每一帧都保存一个完整世界的瞬时状态快照。
回放系统
UDP包大小 是有MTU限制的,然而回放流却没有这个限制,每一帧可达几百上千K字节,直到内存耗尽。
恰好合适的全量快照
但是我们如何保证每次都能得到恰好合适的全量快照呢?

很容易,假装发给回放快照接收者的每个包都丢了就行,然后把永久脏集合重新复制发给回放接收者。这样就可以保证每个快照上每一帧上的每个实体都是脏的。但是就像我上面提示过的,这样做太浪费了。
曾经提到过网络系统是有增量编码的,所以可以基于先前已确认的状态来优化网络流量。
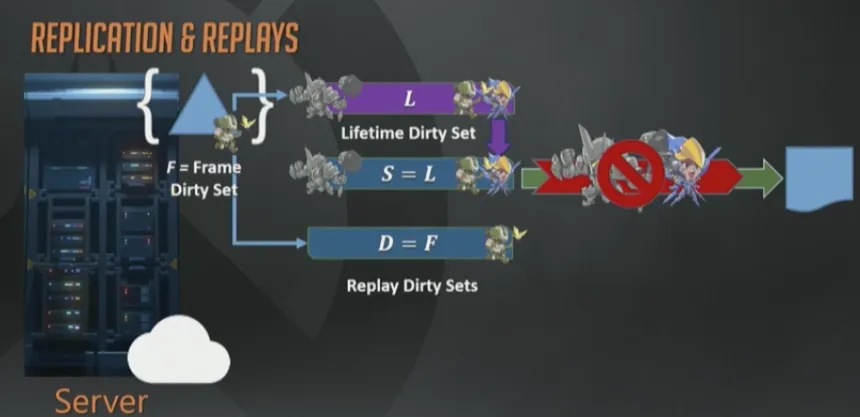
我们又弄了第二个回放接收者,Delta接收者D。这个接收者从不丢弃假想包,每次更新都只包含上一帧到现在的变化。所以基本上直接复制帧脏集然后序列化即可。
现在合起来看一下。

帧的结尾,我们会把新的永久脏状态集合赋值给回放快照目标。同样也会把每帧脏集合序列化给回放Delta目标。然后马上就会有个问题出现:这些数据最终都去哪了?

客户端正常接收者是通过网络包进行的,而回放数据需要通过别的途径。我们维护了两个连续的缓冲区,一个是给快照,一个给Delta。每一帧都会记录这两个缓冲区的偏移和尺寸。
这些连续的缓冲区在整局游戏运行期间都会存在,因为策划可能需要游戏开始到现在的一卷全场最佳镜头(reel,一段连续的影像,无法直译,下文只好统称为“卷”)。
实际看来,每个缓冲区每分钟需要1M的内存,而每帧记录快照所需的内存量比一分钟1M要多得多。所以我们把快照频率降低为每秒1个。
你们中可能有些人想知道Delta的更新频率。服务器的频率是以62.5赫兹(16ms每帧)更新的,死亡重播和回放系统如果都运行在这个频率会使内存和带宽消耗达到3倍之多,所以我们把Delta的频率降低到20Hz(注:即服务端会以60hz的频率更新要发往客户端的Delta,并且会以20hz的频率往客户端发送这个Delta,高帧率模拟+记录来保证计算结果更加准确,低帧率发包可以节约宝贵的带宽)。

现在我们终于可以生成回放“卷”(replay reel ,译注:reel这里强调是“卷”)了,这是客户端所需的核心驱动数据。策划同学想要生成阵亡镜头或者全场最佳的时候,他们请求一个“卷”即可。这些”卷”由一个快照加上一系列递增的Delta组成。
生成回放卷
要生成”卷”,就要找到”卷”所需开始时间之前的最近的那个快照,然后不停添加Delta直到”卷”的截止时间。这里输出缓冲区的生成也很高效,就是2次内存拷贝而已。
缓冲区会被压缩,添加一些元数据,然后发给客户端。阵亡镜头,亮眼表现和全场最佳都是用的这套机制,而且都是通过这一个System支撑的。
如果这时候你开始怀疑这到底还是不是快照同步了,你绝对是正确的。这是有意而为的。两个World都运转良好:基于状态的模型的十分灵活,可以基于客户端网络质量动态调整;快照同步用于回放”卷”时也带来了简洁性。

现在”卷”已经生产,需要发送给客户端了。为了方便传输,”卷”会被切分为MTU大小的多个片段,然后通过我们开发的BlockTransferSystem在网络上传输。BlockTransferSystem会考虑到网络状况,只有在带宽充足的情况下才会发送。
发送给客户端
当然,玩家死亡期间除了盯着凶手,发怒以外什么也做不了,这一点也让我们松了口气。因为他们太全神贯注了,根本不会注意到因为传输大块数据而引起的微小抖动。
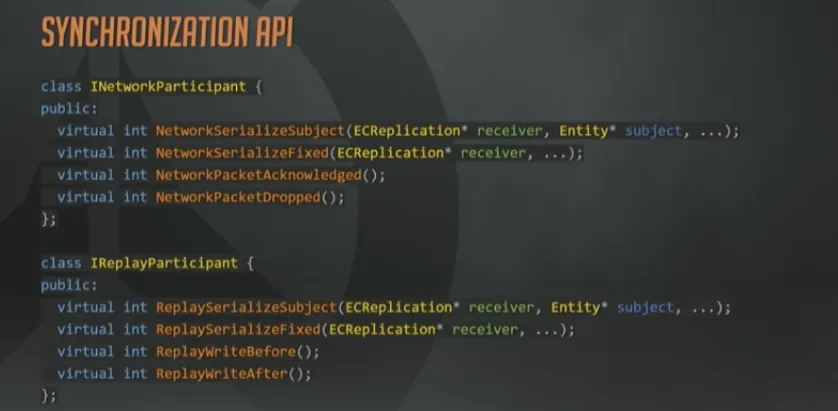
最后看一下同步的API长什么样。这里省略了一些参数;另外返回值应该是枚举而不是整形值,但是用来说明问题已经足够了。
System通常会通过一个内部的通用序列化函数来实现网络参与者和回放参与者两个接口,这两个API的差异很小。例如:网络参与者API会限制带宽,上面已经讲过很多次了。而回放参与者API则完全不用担心这一点。所以很多情况下,回放接口会自行调用含有带宽限制的内部函数,来设置一些永远都达不到的阈值。
网络和回放接口共享序列化策略带来的结果就是,网络复制所节省下的每个字节,在回放系统里也是如此。
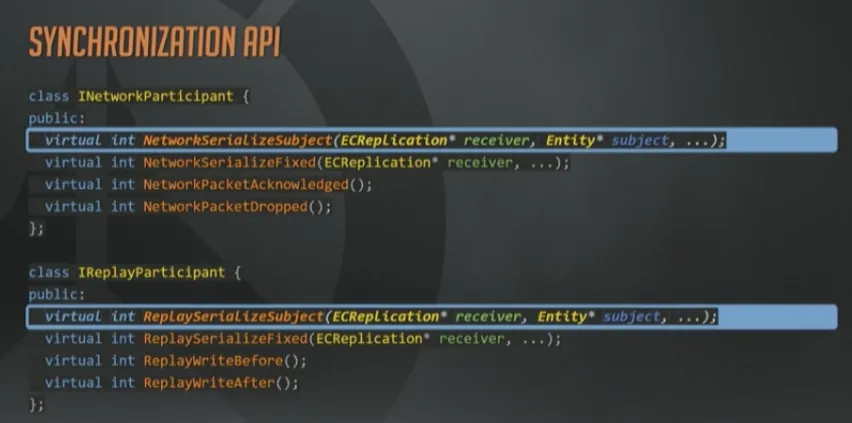
这两个接口是每个接收者,针对每个相关Subject(译注:之前有提到,网络相关实体,就是Subject)分别调用一次的。基本就是每个接收者都遍历一次完整的脏集合了。
如果所有的参与者都认为他们对于某个Subject没有需要序列化的数据了,那就可以安全的把这个实体从接收者脏集合中删除了。
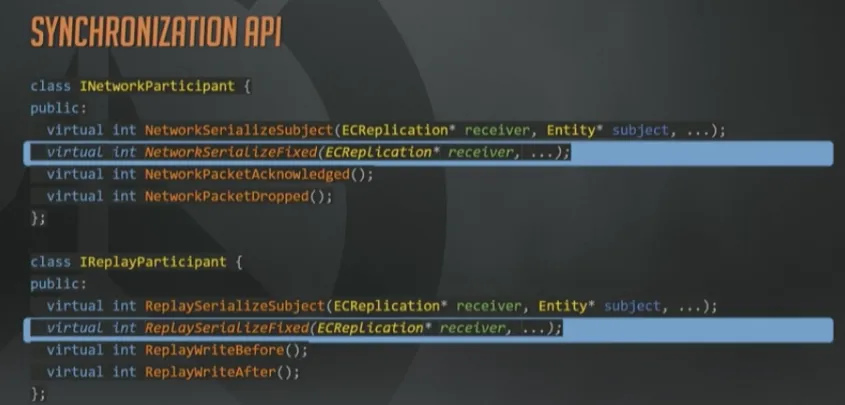
这些带Fixed的函数,给参与者提供了一个机会,去同步那些与实体无关的信息,在网络侧,就包括带外控制消息和握手之类的操作。
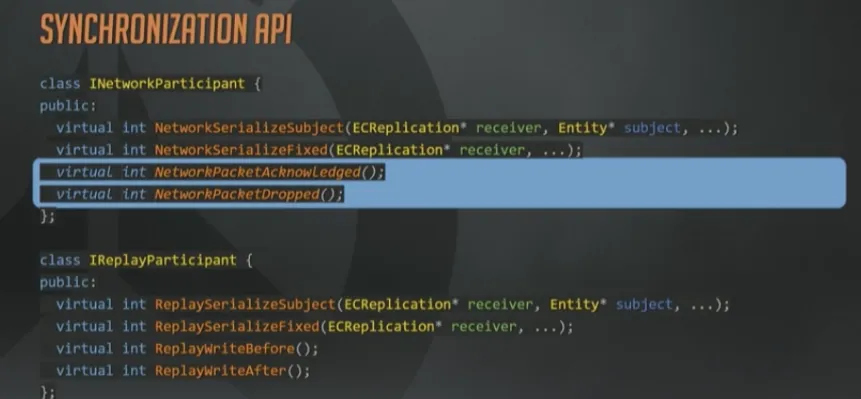
由于采用了不可靠协议,每个参与网络同步的System,对于每个数据包都需要接受一个ACK或者NACK消息,来判断是否收到或者丢失。
我们就是靠之前已经确认收到过的状态,结合内部帧压缩来增量的发送更新。
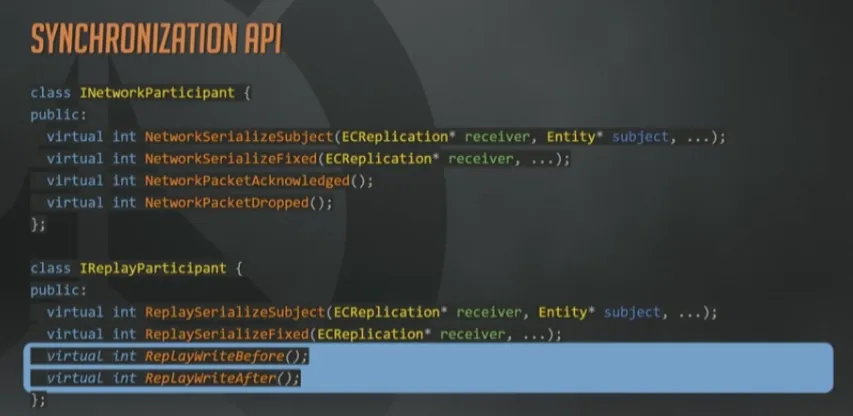
另一方面,回放参与者完全不需要收包确认和丢包通知,因为它们从不“丢”包。取而代之的是在序列化过程开始前和结束后使用一对回调函数。如果要举例说明,如何在完成回放帧的序列化之后立即使用这些函数,那就是,对所有来自Delta接收者的内部序列化状态立即ACK,对所有快照接收者上的数据立即NACK。

上图是发送数据给网络接收者的API使用的简化版用例。对于该接收者的每个参与者,都执行 Fixed调用,然后获取到该接收者的脏Subject集合,并允许每个System都参与到Subject的序列化过程。
这个例子忽略了很多技术细节,而这些细节几乎可以拿出来单独开设分享议题了,包括:脏状态追踪,相关性,优先级,过滤,带宽模型,丢包与确认,以及其他能单独分享的技术。

回放Before和After的API调用例子。

现在回头看一下参与者API,大家可能会有疑问,为什么这些System的设计没有基于组件,而是基于实体 ,而一个良好的ECS架构实现应该是基于组件的。起初我们的同步API确实是基于组件的,例如MovementSystem简单遍历所有Mover组件然后序列化即可。不幸的是,这种范式有些潜在的关联,假如带宽受限会发生什么呢?通过组件序列化意味着一个System就有可能扼杀其他System序列化能力。除此之外还增加了同一实体被多个包更新的可能性。所以我们团队的实用主义者在这个案例中,从纯粹的ECS转向了非纯ECS,而且是完全可以接受的,也是为了更好地玩家体验。
挑战

好了,上面讲过的都是干货,现在来点好玩的:挑战和躺坑。如果说之前讲的是“如何做”,那么现在讲的就是“何时”与“何地”,而“为什么”,最开始我就说过了。
首先,何时下发阵亡镜头的”卷”?阵亡镜头有几个固定时间点:死亡、重生。

这两个点之间的距离是由重生定时器控制的,不同的地图、游戏模式、是否加时及所有策划可以配置的情况下,这个定时器的值都不同。
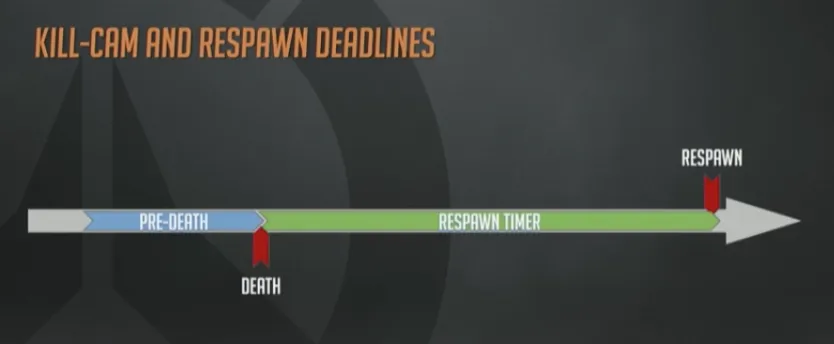
为了使得阵亡镜头看起来更合理,下发数据时需要比死亡那一刻再超前一点点,这样看起来就没那么突兀了,避免出现一脸懵bi的情况下突然被人爆头。

另外,我们也不想在玩家死亡的那一瞬间就突然停止回放,那样会很突兀,因为你的大脑需要一些时间来处理上下文,最好能看到死亡后几秒钟内周围都发生了什么,看着尸体布偶化,然后再从死亡的痛苦中恢复过来。

现在这幻灯片越来越拥挤了。
在死后的尾声阶段,和重生之间,才需要观看阵亡镜头,对吧?这本来就是要开发阵亡镜头系统的真正原因。
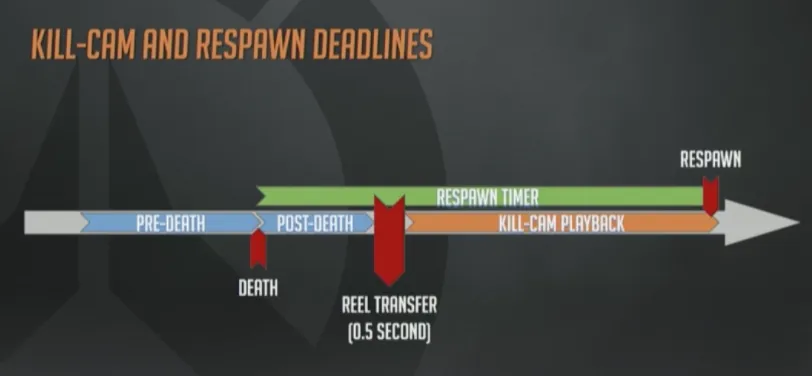
所以这里只剩下一个很小的时间窗口,可以让我们把回放数据发下去。大概是半秒钟左右的时间。然而在低带宽条件下,半秒钟是不够传输数据的。
这些情况也进一步地促使我们开发团队节省带宽。事实再一次证明,我们用来减少带宽消耗的所有努力,同时也减少了回放数据的大小。实践中,我们严格遵守这个纪律,最终实现了一个可靠的阵亡镜头体验,即使低带宽高丢包的网络环境下也是如此。

这里我们还有另外一种选择,与其一次性传输大块数据,不如分开成几次:死亡时立即发送死前(pre-death)数据,之后再陆续下发增量Delta数据。
这个方法会需要一些工程上的折衷,总带宽消耗会变大,因为没办法对整个“卷”进行压缩了。另外还需要一些控制逻辑:即使收到阵亡镜头的第一个数据块也不能立即开始播放,因为数据还不足够,有可能引起回放镜头卡顿,没人想要这种体验。
所有困难都是可以克服的,我们也不一定非要这样做,不过这也是选项之一。
哦,这部分是我的最爱:可打断的阵亡镜头。“复活”是个麻烦事,因为我们已经把“卷”发给客户端了,客户端也开始播放了。但是因为回放随时可能被取消或者打断,所以我们不能完全销毁live世界的状态,也不能停止接收live的网络数据,因为live的游戏脚本可能会需要根据这些数据控制UI、特效,触发事件来表明你被“复活”了。
我们没有使用快照同步模型,所以没办法保持住整个世界的状态,我们没做过类似的游戏,也从来没有实现过。
回放可能立即就会被打断,怎么办呢?

我之前提到过Overwatch的游戏架构用的是ECS,于是乎我有了一个想法,为什么不弄一个独立的”域”(domain)来实现回放呢?或者用Overwatch的术语来说,一个独立的EntityAdmin。通过这两个不相干的ECS域,我们可以把回放和live环境隔离开来。
最后问了一圈,从工程师到团队领导,到技术总监,我基本可以确定在我们这个游戏项目中,CPU绝对不会成为瓶颈。不过这也可能是错的,我的意思是,永远不会成为计算密集型(sim-bound,可以参考CPU Bound和I/O Bound的定义)程序,看起来是那么的明智。

而且对于我们来说这是一个清理旧架构中设计不合理部分的机会,例如对全局变量和静态变量的内部依赖。有了两个完全不相关的域以后,所有的参数都需要限制在域的范围内,所以借此机会整理代码也不错。
大概花了几周的时间,我们把所有东西都隔离了,并且有了两个域(Domain),一个做实时游戏,一个做回放。在这个模型里,实时游戏数据来自网络,直接进入实时渲染的世界里。而来自回放的数据块直接进入了回放模块。进入阵亡镜头时,实际上两个域的数据都在同时处理。
这一页的视频里会演示一个简单的阵亡镜头。回放开始时会有一个黑色淡入效果,这代表我们停止运行实时游戏,转而渲染回放域,等到回放结束时又会转移回去。

总得来说执行“域”的实验很成功,或许是过于成功了,所以我们就在想,既然2个域是ok的,那为什么不搞4个呢?
实际上这并不是一点代价都没有的,我的意思是说,我们需要实现一套机制,可以在过渡时,供域之间进行协调、通信。现在大部分域内部冲突都依赖于EntityAdmin这个全局管理器,通过脚本化行为来协调何时进入何域。
那么这个额外的模拟过程的代价又是什么呢?我们最终还是计算密集型的了,尤其是在主机和低端PC机上。多域模型带来了这个额外负载,但它绝不是唯一一个打破性能预算的系统。有了回放系统以后,我们就可以用录像文件来做整体性能优化。
录像文件使得我们可以直接在主机上发布60帧的FPS游戏,也在低端PC机上达到了性能目标。
就像《辛普森一家》里说的:回放系统,既是性能问题的罪魁祸首,也是救世良方(译注,原剧台词:To Alcohol! The cause of… and solution to… all of life’s problems.)。
遇到的坑
继续讲下打磨过程,这一部分最后才讲,也是我最喜欢的一个话题。
先说炮台吧,对于我们来说,炮台击杀敌人是个棘手问题。建造炮台的玩家会得到击杀奖励。炮台杀人的时候,主人可能已经在半个地图以外了。更糟的是,主人在这时候被干掉了。
下面就是一个托比昂的炮台拿到全场最佳的例子,炮台杀人无数,咱们可以数一下它杀了几个。
一个。
两个(注意视频里托比昂死在了悬崖边上)。
三个(众笑,因为这时候托比昂的尸体已经掉到悬崖中部了)
真的很滑稽,这段视频是从beta版来的,那时候我们还没修复这个bug呢。后来我们就不再把全场最佳送给死掉的英雄了,也就解决了这个问题。(译注,守望先锋最初的版本确实有这类全场最佳镜头,也是十分搞笑)
所以,托比昂视角的阵亡镜头(译注:感觉这里有点问题,作者强调的应该是全场最佳),只有在他自己而非炮台杀人时才有意义。
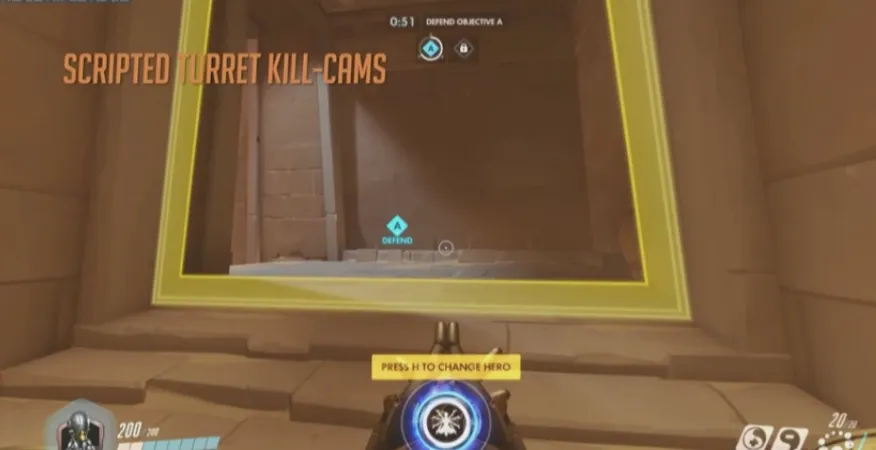
那么该如何处理(炮台击杀时的阵亡镜头)呢?基本上是脚本硬编码的。我们最初调整了炮台的阵亡镜头角度,使它看起来是真的站在炮台的视角看的。但不幸的是,炮台是由AI控制的,而不是一个真实的玩家,并没有用第一人称视角在那里打枪。更重要的是,炮台AI与真人瞄准的方式也是完全不同的。
通过创建一个基于炮台动画骨骼的定制化摄像机,我们解决了这个问题。从那个骨骼位置后方一点,发射出一个由点组成的环,来得到稳定的视角。这种处理方式对于秩序之光的炮台(哨兵炮)尤其有用,因为它们很小,经常被放在天花板上,或者角落里、墙上。另外让炮台和受害者都处于画面中也是很重要的。
下面的视频展示了一个炮台摄像机的例子。注意玩家死亡时,尸体布偶化,摄像机自动对准凶手。阵亡镜头期间,摄像机会追踪玩家,他从角落里一露头,就可以看见炮台把他打到人事不省。
这里你还会有个额外收获,可视化的摄像机位置调试信息。这里绘制了一些绿色的点,表示摄像机的朝向,用来在阵亡镜头期间,保证炮台始终位于画面中央的。
最后的提示是关于debug功能的,即使是在回放过程中也依然可用。如果发现bug了,同样可以依赖脚本系统的调试功能去解决。
你应该能注意到摄像机目标位置会有一些插值。可能还有些其他的被掩盖了,但是这些就是基本原理了
下面是一个炮台摄像机未能按照预期工作的例子,发行版本也是如此。可以看见死亡发生时摄像机再次指向了凶手。但是这个例子里,阵亡镜头里的摄像机没有成功地把炮台聚焦到画面中央。
如果你注意到那些天花板上的龙骨,就知道摄像机的位置没办法更好了,实在没办法。
除了炮台以外,还有其他几种情况,需要我们来实现定制化的阵亡镜头。
当你跌出地图边缘时,我们会解除摄像机绑定,然后追踪你的布偶直到沃斯卡亚的冰河里。
如果是因为有人把你推下去,我们就会转而从他的视角回放死亡过程。
说实话我挺讨厌被推下去的。Alright, and I really hate like this.
半藏的神龙之魂,有同样的炮台问题。他甚至可以从重生室里放大,然后他的龙可以飞跃整个地图直到干掉你,然而半藏的本尊还在重生室里潇洒呢。
在这种情况下显示来自凶手视角的阵亡镜头显然没什么意义,取而代之的是我们使用了一个第三人称视角的摄像机去追踪龙的飞行过程,直到杀死你的那一刻 。
实际上还有好几种需要定制的阵亡镜头,但是没时间全部覆盖到了。上面讲的是最常见的几种,对每一种情况进行打磨都使得阵亡镜头的体验更好,可以减少玩家突然被弄死时的困惑。
好吧,插值提示(interpolation hinting)。从服务器的角度来看,进攻者永远都是在“过去”采取行动的,如果没有额外提示的话,客户端播放阵亡镜头时,就会看到准星瞄的永远都是目标后方,这样不好,会导致论坛上很多投诉。
为了修复这个问题,我们在回放系统里记录了每个玩家的插值延迟提示,然后在客户端播放回放期间,把这个和插值延迟缓冲区集成到了一起。这样就保证了阵亡镜头可以准确显示服务器端进攻者的瞄准动作。
接下来我会用“时间缩放”的方式来连续播放两个阵亡镜头过程(内部回放文件支持这么做)。重点观察开火反冲(recoil)那一刻士兵76的位置。Overwatch里,武器的操作是不会有任何延迟的,一旦你扣下扳机,立马就能看到开火特效和其他相关的表现,包括爆炸、拖尾等。
结果就是,因为客户端帧率的粒度较低,你能看见一点点偏离。但是开火反冲却是由该帧脚本精确控制的。
在爆头的瞬间,(从视频中可以看出)目标刚好处于准星的位置,完美。
再看看同样的情况下,没用插值的表现(译注,从视频上来看,这种情况下,目标已经越过准星了,弹道和击杀提示才出现)。
快进

好吧,现在讲一下”快进”(fast forwarding)。前面已经说了每秒钟记录一次快照,而死后还有2秒的收尾过程(译注:正如前面讲的,摄像机对准凶手,再看看周围环境的变化)。会发生什么呢?如果所需“卷”开始之前最近的一次快照,超前了整整1秒的话(译注:也就是说,“卷”开始时,该快照刚好结束),收尾过程会被截短只剩下1秒,完全不够你用来思考世界的。
解决方案就是把回放过程快进到“卷”开始的时间。这是个很小的工作,却很重要,保证了阵亡镜头体验的一贯性。
此处没有视频举例。
服务器步进

服务器超载时会落后1到2帧然后再赶上来。这种情况下,当前模拟的帧可能得不到所需要的时长了。如果此时客户端执行回放的话,它能得到的帧数就会比预期要少,实际表现就是回放结束的很突兀。
解决方案也很直接,我们在beta版 的客户端采用更高的帧率。同时记录客户端期望时长和服务器实际时长,这样的话就可以在期望的时间窗口内完成回放。

游戏中大多数消息都是针对单个玩家的,回放系统只需要其中的一部分消息,观战者也有同样的问题,不是所有发给指定客户端的消息都应该分发给观战者。
为了实现这一点,我们把每个游戏消息都加上注释,来指定它是否需要被包含到回放或者观战数据流当中。然后在把这些消息委托给适当的接收者。
客户端实际回放期间,我们会过滤掉那些不是发给当前主体的消息。
如果没有这些打磨的话,“卷”里就会缺失受击提示、命中确认、UI变化和一些语音对话。这些处理帮我们改善了回放的体验。
未来的工作
提高Delta录制频率
之前有提到过,我们的Delta刷新频率是20HZ,这基本上是精确度期望值对带宽消耗妥协的结果。顶级玩家可以做到(也的确这么做了)在快速旋转的同时进行射击,但我们当前的频率达不到那么精确。
一个办法就是在回放数据里增加一些朝向提示,就像插值提示那样。另外一个办法就是加快Delta录制频率,使之能够配合当前上下行包的频率。这两个方法都会使得带宽与存储空间的消耗急剧增长。玩家移动的数据包约占到总带宽的一半。
那为什么这会是个问题呢?这里我找了一个游戏高手,人非常好,在录制完成最终的视频以前,一遍一遍地尝试爆我的头。他有一手绝活,你可以看见准星经过爆头点。但是因为没有更细粒度的Delta更新,我们只能用插值填满这50毫秒的范围。
这是实时录像,他真的有那么厉害!This is real-time, yeah he’s that good.
慢动作(slo-mo)再看一遍,“I have so much to live for her”(译注:一句歌词,作者哼唱起来了~~~)。
注意,准星虽然经过了头的位置,但是这里就能看出增加Delta的重要性了(译注:视频中弹道已经明显偏离准星位置了,就是因为Delta的频率不够高所致)。
优化回放文件

快进,倒带,拖放 (scrub,随意指定开始位置去播放)。当前的回放文件,只在起始处有一个快照,所以它其实就是一个普通的基于输入的回放机制,你唯一能做的就是从头向后顺序播放。
正因为如此,就不可能支持拖放,快进也是通过从头开始快速播放实现的,而且倒带实现方式也不咋地,真正想用这个功能的人一定很失望,因为还是从头快速播放到你想要的位置之前多少秒钟。
目前都是团队内部在使用,但是不能排除将来会发布的特性会用到这些。

这一页给出了一个简洁的修复方式:插入更多快照!
考虑到目前快照的尺寸,我们大概可以在回放文件里增加几个10秒钟粒度的快照,在不用对文件尺寸做过多妥协的情况下,至少可以以10秒钟的步幅做快进。

如果我们真的在回放文件增加那些快照,会有一个额外的好处:可扩展的观战功能。增加一个代理或者服务器,与实时游戏服务器独立开来,专门接收带Delta的回放快照即可。越来越多的玩家都想要在诸如锦标赛之类的比赛中实时观战,只需要下发快照给这些玩家,然后不断塞Delta数据流给他们就行了。所有这一切都发生在一个隔离的服务器上,完全不用担心实时游戏服务器过载什么的,这一点非常非常重要。
增加一点缓冲区,画几个UI再加上可扩展的观战功能,这事就成了。当初设计这组内部功能时,真是太明智了。
尽管后来发现,我其实没那么聪明,这个点子也绝非原创。它的实现方式与Valve公司的那个叫做“Source TV”的观战系统如出一辙,我猜Dota2的游戏内观战也是基于这个架构的。
给玩家用的回放
最后,如果不谈一下把回放系统开发给玩家使用,那就太过分了。玩家需要回放,而我们希望玩家开心,做到以下几点就够了。

老实说,最大的阻碍就是找到一种方法来保留全部回放数据。
根据当前帧率,一周的回放文件大约需要200TB的存储空间,这还是压缩后的。不幸的是,压缩需要消耗CPU资源,而CPU是我们当前最大的瓶颈。
除此之外,这200T数据也不是需要永久保存的。我们现在正在研究如何在存储需求和留存(retention)需要之间做权衡,以使得这个功能尽快上线。
我们希望可以允许玩家保存一段合理的时间内,把回放文件保存在他们自己的机器上。我们也考虑过允许玩家在比赛结束时下载回放文件,但是那样会增加本已捉襟见肘的服务器带宽资源,所以也行不通。

谈到留存,就不可避免的提到补丁和序列化兼容性问题。为了能够序列化,网络和回放数据的结构定义,都依赖于资源定义。如果补丁中含有任何与stream有关的东西,都会使得回放文件失效。
从2016年5月游戏发布到2016年12月份,我们打了大概22个补丁。也就带来了22个潜在的不兼容的可能性,谁都不希望看到。
所以我们的客户端必须支持加载上一个补丁版本的资源的能力,这样才能正确播放回放文件。这也意味着,如果硬盘上没有所需资源,就要从网络上下载。还要支持某种形式的新旧版本资源覆盖。从CDN按需下载,显示进度条,需求越列越多。
我们到现在还在想象这个功能应该做成什么样,但是这多少会给你们一些信息,了解我们正在克服哪些阻碍,突破什么边界。
总结
快要结束了,现在回顾一下。
回放系统很酷,上面的例子已经展示了我们影院级的回放镜头支持。
耶,子弹时间!想象一下,把这个功能和一些时间压缩、暂停技术相结合,就能得到类似电影《黑客帝国》中的子弹时间。在我们游戏玩法预告里,大量的采用了这个功能。所以这里取消暂停,旋转一下摄像机,这样就有了一个更好的角度。

到目前为止都学到了哪些知识呢?设计网络同步模型时就考虑到回放的需求;不相关的执行域提供了更大的灵活性和隔离性;网络带宽优化重于回放文件尺寸优化,能省一个字节就省一个字节;社区都很喜欢分享亮眼表现和全场最佳,能在Reddit和其他论坛上看到这些分享,感觉真的很棒。

如果你在开发时不支持回放文件,那就太悲惨了。你应该说服你的工程师,或者如果你自己就是工程师的话,你真的应该先实现这个功能,对于debug来说太有用了。回放文件对于性能分析也很有用。可以提早优化,使得游戏可以运行于任何硬件。

学到的教训。更多的域意味着更多的负载。这一点绝对有些意外,让人头疼,在域之间平滑过渡,就需要大量人力开发。我们做了很多工作去保证,无论什么背景场景,场景更新都保持在一个低频模式,以减少CPU的消耗。
服务器定制的序列化很昂贵,定制越多,优化就越多。如果你决定采用这种方式的话,就要对困难有所准备。
最后一件事,你或许已经注意到幻灯片里的API与发行版本用的很相似。所以,一定要尽早开发同步模式,这样的话API会干净很多。
就这么多了!(掌声)现在是提问时间,看起来我们还有9分钟。
问答环节
Q: 游戏里有很多可破坏对象,那么记录快照时会记录多少呢?全部嘛?
A: 是个好问题,破坏是个很有趣的玩法。游戏刚上线时,可破坏物还不是实体,我遍历了所有的实体序列化后发现,大约是3个月前,偷偷上线了一些改变。推翻了以前的想法,因为有太多的变化了,使得快照尺寸变得很大。所以我们只记录了从“未破坏”到“破坏”,一个bit就够了。我们用一个可破坏的bitmap来代替之前基于地图的数据结构。这个bitmap可以全量同步,总共200个字节。每次有变化发生时,用8个bit来表示变化范围,这样就优化了很多。
Q: 星际2里也有回放系统,你们用到了吗?有什么坑嘛?
A: 星际2是基于帧同步的,它们的回放系统是每次都从头开始,然后快进的方式,同时也实现了回放文件的保存功能。
因为我们并不是帧同步的,大部分原因我在一开始就讲过了。玩家一多,缺点更明显。我们确实跟星际2的团队聊过,正是因为它们的建议,才有了我们最终的这个方案。
Q: 你做了基于组件的序列化,试过按照时间粒度进行序列化嘛?例如你之前提到过的旋转的例子,有得到什么好处嘛?
A: 事物的时间准则非常有趣,我们现在对带宽的使用已经很小心了,没必要再把什么东西从包里剔出。一般来讲发生在一帧内的变化,都能用一个包就装下,所以我们没必要做什么会引起麻烦的修改了,那样做就有点过头了。
事实上完全可以这么做,也很简单,我的包里含有全部序列化数据,如果我们再增加一些动态物品或者其他什么东西的话,就有必要考虑了。
Q: 我这里有个很特殊的问题,我会尽量解释的清楚一些。我调整了准星,然后我注意到在回放里面,无论是谁打你,都没有采用本地玩家设置,所以我想是不是忽略本地设置了,但是我很好奇为什么只有回放是这样子的?
A: 从我的角度看,什么时候用哪个准星,这是个设计问题。如果策划想在回放里使用玩家本地准星设置,那我们就会在回放系统里包含进来。比如说在锦标赛里提供这个功能。
事实上我们现在没有这么做的技术原因就是那个执行域没有你的设置信息。
Q: 说到基于物理的模拟,像尸体布偶或者禅亚塔的佛珠掉到地上,你们是用物理引擎重新模拟还是用了关键帧动画?
A: 客户端和服务器物理模拟过程是分开的。像禅亚塔的佛珠、头发和布偶,都是只在客户端处理的。我们不是像《光环》那样做的。我们确实尝试去同步布偶的数据,所以你可以射穿布偶,在我们的引擎里这不是个问题,取决于是否优化。只是增加一些带宽消耗而已,完全能实现。
 微信
微信 支付宝
支付宝