新时代 AI Agent 开发心法
前言
最近这段时间一直在做 AI Agent,越做越觉得这事和最开始想的还真不太一样。
一开始大家很容易把注意力放在 Prompt 上,觉得只要规则写得足够细,模型够聪明,事情就能办成。讲道理,这个阶段当然是有用的,尤其是单次任务里,Prompt 写好一点,结果立竿见影。
但真把 Agent 放进一个持续运行的业务流里,问题就完全不是这么简单了。
它不是问一次答一次,而是要拿数据、调工具、过规则、看日志、做验证,失败了还得知道从哪里重新来。这个时候你就会发现,大模型本身只是其中一环,真正决定 Agent 能不能稳定跑起来的,反而是那些看起来很无聊的工程细节。
所以这篇文章就先记一下我目前开发 AI Agent 的一些体感。后面想法肯定还会变,但至少现在看,这几个点已经不是锦上添花了,而是地基。
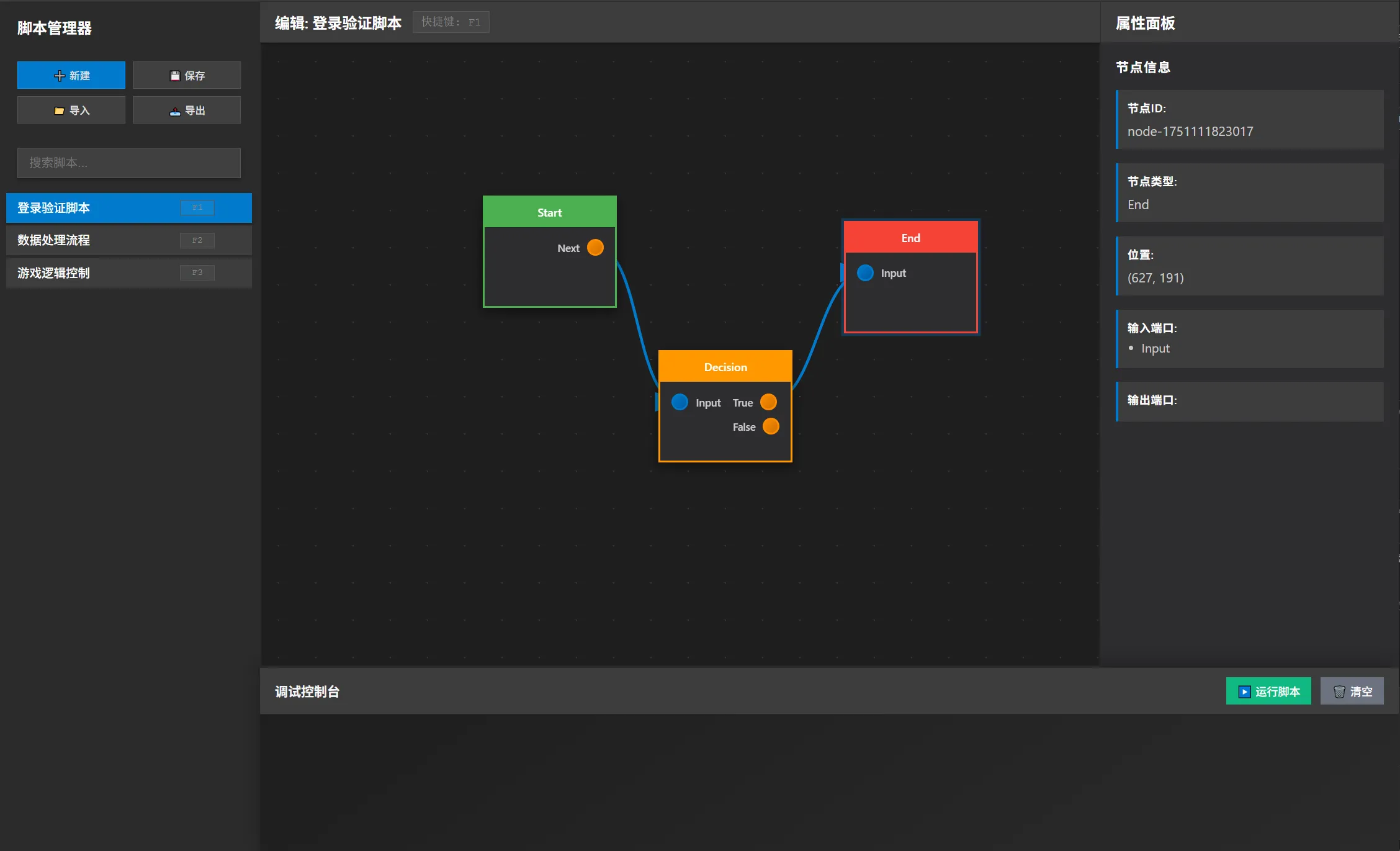
Harness AI
最应该放在第一个讲的,我觉得还是最近提到比较多的 Harness AI。
如果说大模型提供的是推理能力,那 Harness AI 更像是把推理能力接进真实业务流程里的那套线束。它关心的不是模型某一次回答漂不漂亮,而是输入从哪里来,数据怎么过节点,什么时候调用工具,调用失败怎么办,日志怎么留,结果怎么验。
这才是底层中的底层。
AI Agent 一旦开始处理复杂任务,就一定会有多个节点、多个工具、多个数据源,也一定会有失败、重试、分支和验证。流程没管好,后面所有能力都会糊在一起。每个节点看起来都在干活,最后结果不对,但你根本不知道问题出在数据、工具、Prompt,还是某个中间节点的判断。
这就很痛苦。
所以我现在越来越倾向于先把 Flow 搭清楚,再去谈 Agent 的智能程度。框架搭建、节点边界、日志记录、自我验证,这些东西先做好,后面才有迭代空间。不然就是一团浆糊,AI 越努力,糊得越均匀。
工具拆分
确定性功能工具的拆分,很考验手感。
太细不行。什么小动作都拆成一个工具,表面看是灵活,实际跑起来就是满地零件。Agent 每次都要在一堆小工具里做选择,节点数量也会膨胀,日志看起来密密麻麻,排查问题的时候脑子直接开始发热。
太粗也不行。一个工具把获取数据、清洗、解析、校验、生成全包了,短期确实省事,但后面想复用其中一段逻辑,或者替换某个节点,就会发现它像一整块混凝土,哪里都能用一点,哪里都不好拆。
我现在比较认可的拆法,是按稳定业务动作和可复用能力边界来切。
比如数据获取、数据清洗、结构化解析、规则校验、结果生成、结果验证,这些通常都可以成为相对稳定的能力单元。每个工具最好有清楚的输入输出,职责边界也要说得明白。日志里一眼能看出它做了什么,而不是只留下一句“执行成功”。
工具不是越多越好,也不是越万能越好。
颗粒度对了,Agent 好理解,人也好调试。颗粒度不对,后面就会变成工具地狱,谁来都得先在门口罚站半小时。
数据源
数据源这件事,我现在越来越不敢轻视。
原始数据如果不干净,后面流程再规范,结果也很难好看。更麻烦的是,脏数据经过一套完整流程包装之后,错误会变得更像真的。
很多时候大模型不是凭空犯蠢,而是它拿到的上下文本来就有噪声、有遗漏、有冲突。它再顺着这些东西往下推理,最后给出的答案可能语气很稳,结构也很漂亮,但根子已经歪了。
这类问题最烦人的地方在于,它不像程序报错那样直接炸给你看。它会给你一个看似合理的结果,然后等你用到业务里才发现不对劲。
所以做 Agent 时,数据源至少要先问几个问题:
- 原始数据靠不靠谱?
- 字段是不是完整?
- 数据有没有及时更新?
- 不同数据源之间有没有冲突?
- 清洗以后有没有把关键业务语义一起洗没了?
尤其是 RAG、策略推荐、业务分析这类 Agent,数据源质量基本决定上限。Prompt、工具、流程、验证都能提高稳定性,但它们很难从一堆脏数据里变出高质量结果。
说到底,饭都馊了,后厨流程再标准也没用。
联网搜索
联网搜索也不能当成一个可有可无的插件。
它一方面是为了拿最新信息,另一方面也是给整个框架留一个自我更新的入口。大模型自己的知识一定有时间边界,只靠已有知识去处理变化很快的领域,很容易一本正经地说出过时结论。
但是搜索这件事也不能粗暴。
不是把搜索结果一股脑塞进上下文就完事了,那样只是把网页噪声换了个地方堆起来。比较靠谱的做法,是把搜索也纳入 Flow:先明确搜索目的,再筛选可信来源,然后做摘要和结构化,最后让模型结合任务目标判断哪些信息真正有用。
这样搜索结果才不是新的噪声源,而是 Agent 更新认知、修正流程、补充数据的输入。
我现在的感觉是,一个长期运行的 Agent,如果没有联网搜索能力,很快就会被时间甩在后面。尤其是 AI、工具链、游戏版本、社区攻略这种变化快的东西,不联网基本就等着说胡话。
记忆系统
记忆系统这块,我目前比较推荐 Memos。
它的价值不是“让 AI 记住聊天记录”这么简单,而是把历史对话和历史经验沉到一个可以检索的库里。这个东西做得好,Agent 就不是每次都从零开始理解用户和业务。
大概流程是这样:
- 我们可以手动把每一次用户对话记录到数据库里。
- 其他用户在使用对话时,系统可以自动从记忆库里检索相关内容。
- 检索出来的内容再交给大模型判断是否有用。
- 如果有用,就作为当前任务的参考。
这其实就是一种经验回流。
Agent 不再只依赖当前上下文,而是可以从过去的经验里召回相关信息。只要写入、检索和判断机制设计得合理,系统就会越用越懂业务,也会少掉很多重复解释。
当然,记忆也不能无脑塞。不是所有历史对话都应该进上下文,也不是所有检索结果都值得信。比较好的做法,是把召回内容当成候选参考,最后仍然让模型结合当前任务、来源可信度和业务规则做判断。
记忆系统要是做不好,也会反过来污染 Agent。它会一本正经地把旧经验、错经验、无关经验拿出来当宝贝,这就和脏数据是一个问题了。
让 Coding Agent 自己迭代 Flow
再往前走一步,我觉得 Coding Agent 本身也应该能迭代 Flow。
也就是让开发 Agent 的 Agent,反过来优化 Agent 的流程。
它可以不断跑当前 Flow,拿到运行结果,再根据节点日志分析哪里还能改。比如某个节点经常失败,某个工具调用成本太高,某个验证总是不通过,某段数据清洗逻辑老是丢关键信息,这些都可以成为优化依据。
理想状态大概是:
- 执行当前 Flow。
- 收集每个节点的输入、输出、日志和错误。
- 判断失败原因或低质量原因。
- 在一定准则下修改工具、提示词、节点顺序或验证逻辑。
- 重新运行 Flow,对比前后效果。
听起来像是让 AI 自己改 AI,但重点不是完全放权,而是给它一个可验证的闭环。
只要评价标准清楚,日志完整,修改可回滚,还有稳定的测试样例,Coding Agent 就可以在相对安全的范围里优化流程。它不只是帮我们写代码,而是在帮我们维护整个 Agent 系统。
这块我觉得会很有意思。以后 Coding Agent 不只是“执行者”,也会慢慢变成 Flow 的维护者和调参师。人负责定边界和评价标准,它负责在边界里开干。
人工监督
当然了,人工监督还是少不了。
很多时候 AI 并不知道当前业务下什么才算最优解。它可以推理、总结、生成方案,但有些规则必须由人定义,甚至要写成数据驱动的硬规则。
比如最近做英雄联盟相关 Agent,会遇到「日炎」和「璀璨回响」这种互斥关系。两者只能同时出一个,这个规则如果不写进数据里,AI 很难凭空知道,更难保证每次都稳定遵守。
这种问题不能只靠 Prompt 兜底。
更可靠的方式,是把业务约束结构化:
- 互斥规则写进配置或数据表
- 数值边界写成可验证规则
- 输出结果经过确定性校验
- AI 只负责在规则允许的空间内做推理和生成
这样才能把 AI 的灵活性和工程系统的确定性接起来。
说实话,我现在越来越觉得 AI Agent 落地不是“完全相信 AI”,而是让 AI 在一套清楚的流程和规则里发挥能力。人负责定义边界、准则和目标,AI 在边界内探索、组合、执行和优化。
这才比较靠谱。
nkg AI Flow
目前实践下来,用我们现在开发的 nkg AI Flow 做这类 Agent 开发,确实挺顺手。
它把 Flow、工具、节点日志、自我验证这些东西放在一个适合迭代的结构里。这样我们不是每次都从零写临时逻辑,而是可以把经验沉淀成稳定的流程资产。
更重要的是,我也把这些经验整理成了一个 skill。后面大家可以直接让 Coding Agent 使用它,让 Agent 按这些原则去拆工具、跑 Flow、看日志、做验证,再继续优化。
我比较看好这个方向。
不是只让 AI 生成一次结果,而是让 AI 帮我们持续建设一套更可靠的工程流程。这个过程肯定不会一开始就很完美,甚至前期会有点折磨,但只要 Flow 能跑,日志能看,验证能闭环,它就有持续变好的空间。
总结
这篇先写到这里。
简单收一下,目前我觉得新时代 AI Agent 开发里最绕不开的几件事是:
- Harness AI 是流程管理的底座。
- 确定性工具要拆得合理,既不能拆太碎,也不能包太死。
- 数据源质量决定最终效果的上限。
- 联网搜索是获取最新信息和自我迭代的重要入口。
- 记忆系统可以让历史经验变成可复用资产。
- Coding Agent 应该能基于日志和验证结果持续优化 Flow。
- 人工监督和数据驱动硬规则仍然不可替代。
后面我也会继续更新自己在开发 AI Agent 路上的一些心得。现在先记到这里,免得过段时间又忘了自己是怎么踩坑的。
 微信
微信 支付宝
支付宝